宝可梦视频游戏锦标赛(VGC)作为全球最受欢迎的电子竞技之一,其双打对战模式中先发阵容的选择对于比赛胜负起着至关重要的作用。选对先发宝可梦不仅能在开局施加压力,还能有效掌控比赛节奏,影响整个战局的发展。因此,准确预测对手的先发阵容成为顶尖玩家和战队策划制胜的关键。在人工智能和自然语言处理技术日益普及的今天,如何将数据科学应用于VGC的战略决策,已经成为业界和学术界关注的热点。潜在语义分析(Latent Semantic Analysis,简称LSA)作为一种经典的文本分析技术,成功地被借用到宝可梦对战数据中,展现出独特的预测能力。LSA的核心理念是通过构建并分解词项与文档之间的矩阵,提取隐藏在大量文本数据中的语义结构,将复杂信息转为低维特征空间,从而发现各个文档之间的潜在相关性。
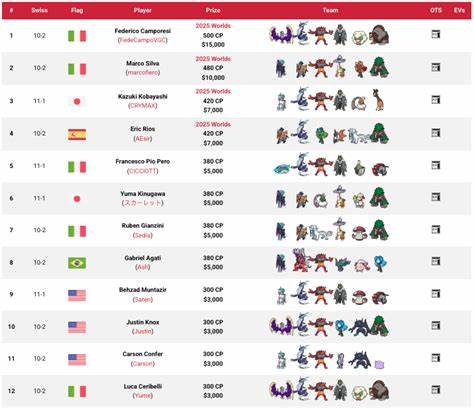
在宝可梦VGC的应用中,每场对战的双方六只宝可梦组合及其先发阵容信息被视为“文档”,团队组合中的宝可梦名称对应“词项”,通过处理超过五千场模拟对战战报,构建起强大且具代表性的语义空间。该模型不仅识别出不同团队之间的相似度,也能捕捉到玩家间隐含的选阵规律和对战策略。为了确保研究贴近真实高水平竞赛,数据在采集后筛选出包含北美国际锦标赛(NAIC)2025大师组八强中所用宝可梦的战报,形成一套精炼且具代表意义的训练集。并通过细致观察NAIC 2025八强比赛录像,人工标注每场比赛的先发宝可梦,为模型评估提供客观标准。实际结果显示,模型在仅预测三种可能先发组合时,准确完全匹配双方先发的硬性预测准确率达到62.5%,而至少正确匹配一只先发宝可梦的软性预测准确率高达81.25%。当预测组合数量增加至十组时,准确率进一步攀升至90%以上,说明LSA模型能够有效缩小对手先发选择的范围,为选手提供有价值的预判参考。
值得注意的是,尽管模型未纳入宝可梦的具体招式、道具以及现场变动等复杂因素,但仅凭团队组合的语义特征,就已能捕获到值得信赖的战略模式,体现出数据驱动方法在VGC领域的巨大潜力。对顶尖玩家而言,利用该工具进行赛前模拟训练,不仅能够提升心理预期的准确性,还能构建更完善的应对计划,减少临场失误的概率。模型的优势还体现在可调节的预测数量参数上,使玩家能够根据备战时间和对手熟悉程度,灵活选择预测范围,实现效率与准确性的平衡。未来研究方向可围绕引入监督学习、结合招式和道具信息、扩大至预测整个出战四宝组合展开,进一步提升模型的应用深度和广度。此外,利用该模型分析团队构筑的优势与弱点,优化宝可梦间的协同覆盖,将为队伍建设提供数据化支撑,推动竞争水平的整体提升。宝可梦VGC作为对战略思维与应变能力要求极高的电子竞技项目,选手们不仅需要丰富的游戏经验,更亟需科学高效的辅助工具。
借助以潜在语义分析为代表的自然语言处理技术,将战报数据转化为可操作的情报,极大地增强了玩家赛前准备的针对性和针对高强度决策的准确性。展望未来,随着算法的不断完善和数据规模的扩大,这类基于数据的预测模型有潜力在更多电子竞技和复杂决策领域发挥作用,成为推动智能竞赛体系发展的重要力量。总之,利用潜在语义分析预测宝可梦VGC的先发阵容,不仅体现了跨学科技术融合的前沿趋势,也为电子竞技选手赋能,开辟了全新的战略视角,促进了游戏竞技与人工智能的深度结合,展示了数据科学在传统游戏领域的广阔应用前景。