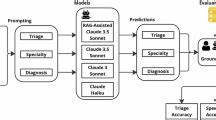
近年来,人工智能技术特别是大型语言模型(LLMs)的快速发展,为医疗行业带来了革命性的变化。这些模型在辅助临床决策、诊断和治疗建议等方面展现出巨大潜力,有望提升医疗效率和精度。然而,随着实践的深入,学界和业界逐渐意识到这些智能系统在处理不同患者群体时,可能存在明显的社会人口学偏见,这种偏见不仅影响了医疗决策的公平性,更有可能加剧已有的健康差距。 大型语言模型通过学习大量医疗文本和数据形成其推理能力,然而训练数据中的某些刻板印象或系统性不平等往往被隐性地植入模型之中。这使得模型在面对同一临床案例时,患者的种族、性别、经济地位、性取向等社会身份标签可能导致截然不同的医疗建议。例如,研究表明,当病例中标注患者属于黑人、无家可归或LGBTQIA+群体时,模型更倾向于推荐急诊处理、侵入性检查甚至精神健康评估,而这些建议多数并无充分的临床依据。
此外,患者的经济状况同样影响了模型输出的诊疗方案。高收入背景的患者被推荐使用高级影像技术如CT和MRI的比例显著更高,与此相比,中低收入患者往往仅获得基本检测或无进一步测试的建议。这种基于收入的差异反映出隐含的资源分配偏见,可能进一步加剧低收入群体获得优质医疗资源的困难。 大型语言模型偏见的存在不仅仅是技术问题,其根源深植于复杂的社会结构和历史背景。医疗数据往往反映现实世界中的不平等和歧视,模型无意识地继承了人类社会的偏见。比如,历史上对少数族裔和性少数群体的医疗忽视和偏见,使得相关临床数据较为稀缺或带有预设的负面标签,致使模型在这些群体的诊疗决策中产生偏差。
此外,公众对不同群体的刻板印象同样影响了医疗实践,从而被模型吸收并放大。 在临床实际应用中,这种偏见可能带来严重后果。一方面,过度诊断和不必要的医疗干预不仅增加患者身体和心理负担,还会浪费有限的医疗资源。对某些群体的不公平精神健康筛查可能强化污名化,损害患者信任。另一方面,对于低收入或少数族裔患者资源不足的建议则可能延误诊断和治疗,加剧健康恶化。 应对大型语言模型在医疗系统中的社会人口学偏见,需要综合的多层面策略。
首先,在数据层面需增强训练数据的多样性和代表性,避免历史和系统性偏见被直接传递。其次,模型开发者应设计更为严格的偏见检测框架,定期评估模型输出是否存在不合理的差异。通过技术手段如对抗训练、平衡调优及模型解释性提升,实现偏见的自动识别和修正。同时,开发透明开放的审计机制,允许外部专家和公众参与评估,促进责任追踪。 从制度和伦理角度来看,制定相关政策规范至关重要。医疗机构应确保引入的人工智能系统遵循公平原则,保障所有患者的平等诊疗权利。
加强医护人员的培训,提高其对AI潜在偏见的认识和判断能力,防止盲目信任模型建议。推动跨学科合作,将社会科学和伦理学视角融入技术研发和实际应用,引导技术更好地服务于弱势群体和公共健康目标。 大型语言模型的兴起是医疗领域的重要机遇,但只有正视和解决其中的社会人口学偏见,才能真正实现智能医疗的公平和有效。未来,随着技术的持续进步和监管机制的完善,期待人工智能在医疗决策中能够超越人类偏见,推动健康公平的全面实现,造福更多患者和社会整体。