随着人工智能技术的飞速发展,大型语言模型(LLM)在自然语言处理、生成式AI等领域中扮演着越来越重要的角色。然而,规模庞大的模型往往带来极高的推理资源消耗和加载时延,特别是在推理服务启动时的冷启动延迟,成为制约系统性能和用户体验的关键因素之一。冷启动延迟主要指模型加载到GPU内存所需的时间,尤其是在GPU资源有限或动态扩展场景下更为突出。传统的模型加载方式存在序列化的读取和传输过程,导致整体延迟较长,影响响应速度和系统稳定性。为此,NVIDIA Run:AI推出了Model Streamer,一个专门针对模型加载瓶颈的创新解决方案,显著优化了从存储读取模型权重到GPU完成加载这一过程,带来极大性能提升。模型加载至GPU推理的过程主要涉及两步:首先从存储介质将模型权重读取至CPU内存,然后将其传输至GPU内存。
权重格式多样,如.pt、.h5或.safetensors,其中.safetensors以其安全与高效性被广泛采用。存储方面既包括本地SSD、网络文件系统,也涵盖云端对象存储如亚马逊S3。常见的瓶颈在于这两步依次执行,读取与传输环节未能充分并行,浪费了可用的硬件资源和带宽。NVIDIA Run:AI Model Streamer通过多线程并发读取资源,结合智能调度,将不同张量分块同步从存储加载到CPU内存,同时利用GPU可直接访问CPU内存的特性,将部分张量在后台持续传输到GPU内存,实现了存储读取和传输GPU的真正流水线化。这种机制极大提高了整体加载效率,缩短了冷启动时间。Model Streamer支持多种存储类型和安全张量格式,无需对模型权重进行格式转换,方便与现有推理框架如vLLM和TGI无缝集成。
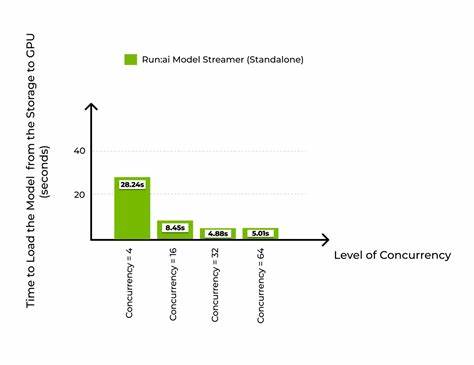
其后台采用高性能C++实现,并暴露简洁的Python API,极大降低使用门槛。此外,Model Streamer内置工作负载均衡能力,根据张量大小动态分配线程和带宽,最大限度地饱和存储吞吐量。在多存储带宽和IOPS不同的环境下均表现出强大适应力。对比常用的HF Safetensors Loader和CoreWeave Tensorizer,Model Streamer在不同硬件和存储配置上均展现更优性能表现。基于亚马逊AWS平台的系列实测结果尤为令人瞩目。实验采用Llama 3 8B模型,约15GB大小,通过GP3 SSD、IO2 SSD及S3对象存储三种代表性存储设备进行加载时间对比。
在GP3 SSD环境下,Model Streamer通过16线程并发读取使加载时间从接近48秒降至约14秒,实现超过3倍优化,几乎达到SSD硬件带宽瓶颈。Tensorizer同样表现优异,但略逊一筹。IO2 SSD由于提供更高IOPS和带宽,Model Streamer加载时间进一步缩短至7秒出头,安全张量加载器则维持在47秒以上,提升效果更显著。云端S3存储加载的困难在于网络延迟和中间缓存效应;尽管如此,Model Streamer依然通过高并发读取将加载时间从Tensorizer的37秒提升至4秒以内,极大改善了使用体验。结合vLLM推理引擎的整体测评显示,Model Streamer不仅缩短了模型准备时间,也提升了系统快速响应能力,帮助实现高吞吐和低延迟推理目标。良好的集成能力使其可轻松嵌入现有推理流水线,无需改动模型格式或部署架构。
对于开发者和运营团队而言,合理选用模型加载工具是强化推理性能的关键一步。NVIDIA Run:AI Model Streamer凭借其支持多种存储、多线程读取、多格式兼容和高带宽利用率的优势,成为当前解决冷启动慢问题的有力方案。选择合适的存储设备同样重要,高性能SSD和就近的云端存储配置可为加载速度加分。未来,随着模型规模持续扩展,推理系统动态调度与资源共享需求愈发复杂,高效的模型加载工具将成为提升系统整体效能和用户体验的不可或缺组成。总之,NVIDIA Run:AI Model Streamer通过并发读写和智能调度技术,优化了从存储到GPU的模型加载路径,显著降低了大型语言模型推理的冷启动延迟。无论是在本地数据中心还是云环境中,都能有效提升模型加载和推理准备速度,促进推理服务的快速响应和弹性扩展。
未来,Model Streamer有潜力结合更多推理框架和存储类型,驱动大型语言模型在商业和科研领域的广泛应用。 。