近年来,随着人工智能技术的快速发展,大型语言模型(LLM)逐渐成为推动自然语言处理领域进步的重要力量。从文本生成到机器翻译,从代码编写到内容创作,各种场景下的应用需求激增,促使不同模型之间的竞争日趋激烈。然而,面对市场上琳琅满目的模型,如何有效对比并选择最适合的语言模型,成为行业和用户关注的焦点。 大型语言模型排名的出现,正是为了帮助用户厘清各模型在不同任务和指标上的表现差异。通过全面的评测体系,排名不仅反映模型在处理多种类型提示语时的准确性和流畅度,也揭示了其在角色扮演、编程、营销、科技、科学、法律、金融、医疗、趣味问答及学术领域的综合应用能力。这样的多维度考量,让用户可以根据自身需求有的放矢地选择最合适的模型。
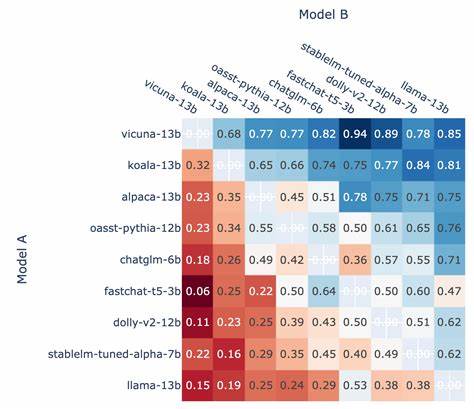
在对比大型语言模型的过程中,令很多用户感兴趣的重要指标包括内容生成的连贯性和创造性、上下文理解的深度、多任务处理的灵活性以及生成结果的专业度。例如,在编程领域,模型不仅需要理解复杂的语法结构,还要具备解决问题的能力;在营销和SEO方向,则更侧重于内容的吸引力和针对用户需求的精准把握。 排名体系通过采集大量用户输入的真实提示语,涵盖各种使用场景,确保对模型的评估更具代表性和实用价值。同时,排名系统还显示了模型的令牌(token)使用统计,通过分析令牌消耗帮助用户合理控制成本,提高效率。在顶尖模型中,我们可以看到它们凭借优异的性能表现赢得了广泛青睐,成为日常工作和研究不可或缺的助力。 除了性能指标外,排名还关注模型的稳定性和响应速度。
这些因素在实际应用中直接影响用户体验,尤其是在高并发或实时交互环境中,快速且准确的回应尤为重要。此外,模型的更新迭代频率也是用户所关心的内容,频繁的升级意味着模型不断优化,能够提升应对新兴语言现象和技术挑战的能力。 在当下市场,多个知名人工智能公司如OpenAI、Google、Meta等纷纷推出各具特色的大型语言模型。它们在参数规模、训练数据和技术架构上各有千秋,通过排名体系的比较,用户得以清晰认识到不同品牌模型的优劣势。例如某些模型在法律和金融领域拥有更丰富的专业知识库,适合行业特定需求;而另一些则凭借出色的通用能力,适用于广泛的文本生成任务。 此外,多样化的使用场景促使模型不仅仅定位于单一功能,而是朝着多模态融合、跨领域智能等方向发展。
排名系统涵盖的类别也随之扩大,涵盖了从角色扮演到科学研究,从翻译领域到健康管理的各类任务,极大增强了模型的实用性和灵活度。用户可根据具体应用需求,选择专注某一领域表现优异的模型,亦可选择多功能型模型以满足多样化工作需求。 在数据隐私和安全方面,评价体系亦不失考虑。对模型在处理敏感信息时的安全保护能力进行测试,确保用户数据免受泄露风险。随着法规日趋严格,模型厂商愈发重视合规性,通过技术手段提升模型的安全防护,增强用户的信任感。 综合来看,大型语言模型排名不仅提升了技术透明度,更为用户提供了科学的决策依据。
在数字经济时代背景下,智能语言模型作为连接人类与机器的桥梁,将越来越深刻地改变信息交流和知识获取的方式。通过排名,我们能够见证技术的演进脉络和未来发展趋势,推动相关产业链健康发展。 未来,随着算法优化和算力提升,语言模型有望在理解复杂语义、跨文化交流及多任务协同方面实现突破。排名系统将继续拓展评测维度,涵盖更多实际应用指标,帮助用户精准测评模型竞争力。同时,社区和开发者的反馈也将成为模型优化的重要参考,促进开放生态建设。 总之,在选择大型语言模型时,借助权威的排名与对比工具,无疑是提高效率、降低成本的最佳方式。
通过深入分析不同模型的技术细节和应用表现,用户能够制定更合理的使用策略,实现语言智能服务的最大化价值。随着技术不断进步和应用场景的丰富,排名体系将持续发挥关键作用,助力行业迈向更加智能化、专业化的未来。