在现代软件开发中,错误处理无疑是保证程序健壮性和用户体验的重要环节。不同语言对于错误处理的理念和实现方式存在显著差异,尤其是以Python的异常机制与Rust的结果类型为代表的两种截然不同的策略。本文将深入探讨其中的差异、优势与劣势,并结合实际代码案例,帮助开发者更好地理解何时及如何选择合适的错误处理方式。 Python 是当今最受欢迎的编程语言之一,其异常系统设计灵活并且功能强大。异常可以打断正常程序流程,迅速向上层传递错误信息,从而使调用者处理错误。然而,这种便利也带来了潜在的风险,尤其是异常的使用如果不当,可能让代码的行为变得难以预测,增加维护难度。
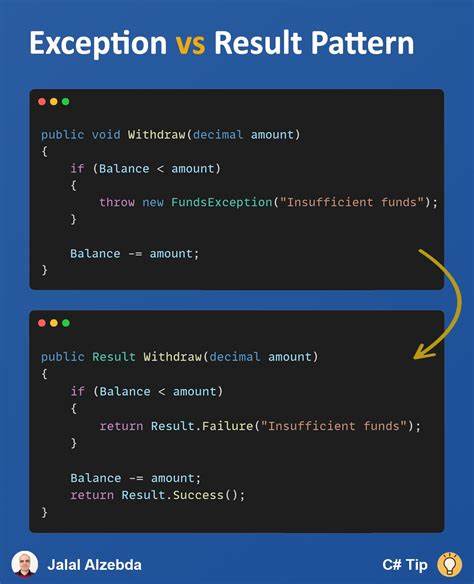
部分资深开发者因此倾向减少异常的使用频率,避免自定义异常滥用,从而降低代码的隐蔽复杂度。 对比之下,Rust 采取了截然不同的设计理念。Rust 坚持显式处理错误,使用 Result 类型封装操作的成功值或错误值,没有传统意义的异常机制。程序员必须明确处理每一个可能的错误,借助模式匹配(match)语法进行分支处理。这种做法大大提高了代码的可读性和安全性,同时强制开发者考虑所有可能的失败场景,避免了异常带来的隐式跳转和潜在漏洞。 许多Python程序员在初次接触Rust时会被 Result 类型的显式错误处理所吸引。
虽然Python本身不强制使用类似的结构,但项目中常会因为第三方API或复杂业务逻辑需要对不同错误类型进行不同处理,令异常机制的局限性显露无遗。举例来说,当调用一个网络请求接口时,可能会遇到多种HTTP错误码,如401表示需要身份验证,404说明资源不存在而应该放弃该请求,而503则适合重试。利用异常处理虽然简洁,但如果异常种类繁多且嵌套复杂,代码可读性和错误追踪能力会急剧下降。 为了缓解这一痛点,一些开发者尝试在Python中引入类似Rust Result的抽象,例如使用自定义Result模式化处理成功和错误分支,结合Python 3.10+引入的match语句实现错误分类处理。通过将函数返回值包装成包含"Ok"或"Err"的结构体,程序员可以在调用端使用匹配语句化繁为简地处理各种结果。这种做法虽然在理论上提供了更加显式和严格的错误管理机制,但在实际Python项目中却显得冗长和不够优雅,违背了Python简洁明了的设计哲学。
从具体的代码实践来看,原始的异常写法在Python中自然且直观。以网络爬虫为例,面对需要重试或跳过的情况,使用try-except捕获自定义异常,可以直观表达业务意图。相反,将所有错误以结果对象返回,则需要多层match嵌套,不但增加代码量,还可能使控制流显得复杂,影响维护性。尤其当错误处理逻辑涉及多个层级或交叉场景,过度依赖模式匹配处理错误会使代码变得臃肿难辨。 另外,Python语言设计者从一开始就将异常视作控制流程的一部分,并为此增加了丰富的异常机制和语法支持。对比之下,Rust的错误处理则强调安全性与显式性,几乎没有例外。
Rust通过宏和泛型支持,最大限度减少错误引入程序崩溃的风险,同时让错误处理成为程序逻辑的显式组成部分。 综合来看,每种语言选择错误处理机制均有其文化及技术背景。Python的异常机制符合其动态性、灵活性和开发效率优先的理念,适合快速开发与原型设计。Rust的Result模式强调软件的安全性和健壮性,非常适合系统级应用和需要高可靠性的场景。开发者应结合项目需求与团队习惯,灵活选择合适的错误处理模型。 值得注意的是,随着Python 3.10引入match语句以及社区对类型提示和结构化错误处理的推动,未来Python中结合Result风格的错误管理可能会有更多尝试与优化,从而弥合部分痛点。
然而,简单、清晰的异常处理仍将是Python生态中主流的错误处理方式。 在实际应用中,经验丰富的工程师往往会用"恰当的工具完成恰当的任务"作为指导原则。在Rust中遵循Result模式毫无疑问,而在Python中慎用异常,避免过度依赖catch-all异常块,同时编写详尽的文档和测试,才是提高错误管理质量的关键。 总结来说,理解不同语言的错误处理哲学及其技术实现,能够帮助开发者写出更健壮、更易维护的代码。Python的异常机制和Rust的Result类型各有千秋,合理借鉴两者的优点,并结合语言原生特性,才能在项目开发中发挥最大优势,确保软件稳定高效运行。 。