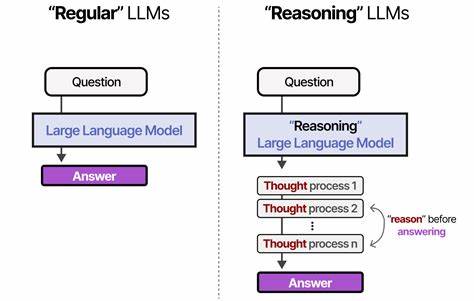
随着人工智能技术的迅猛发展,大型语言模型(LLMs)在自然语言处理领域展现了惊人的能力,涵盖从文本生成、问答系统到复杂推理等诸多应用场景。然而,随着其应用范围的不断扩展,确保模型能够在面对无法回答的问题时恰当处理,成为智能系统可靠性迈向实用化的关键一环。近期发布的研究成果AbstentionBench为我们提供了全新的视角和工具,帮助深入理解和评估大型语言模型在“选择不回答”环节的表现及其面临的挑战。本文将详细探讨AbstentionBench的核心内容、研究发现及其对于未来人工智能发展的重大意义。 大型语言模型在现实世界的应用中,需要面对各类复杂、模糊甚至无法回答的问题。例如,用户的提问可能信息不全、存在矛盾前提,或是根本没有确定性的答案。
这类问题对模型的推理能力和不确定性判断能力提出了巨大挑战。传统评价体系通常只关注模型给出的答案是否正确,却忽视了何时模型应当合理选择放弃回答。事实上,模型如果在无法给出正确答案时硬要回应,就可能导致误导用户,甚至引发严重后果。AbstentionBench正是为弥补这一评价盲点而设计的多维度综合基准。 AbstentionBench集合了20个多样化的数据集,涵盖未知答案、信息不足、虚假假设、主观解释和过时信息等不同类型的“无解”问题。这种设计让模型必须在不同挑战面前做出审慎判断,学习何时要果断“弃权”。
通过对20款当前最先进大型语言模型的评测,研究揭示了一个令人警醒的现象:大型语言模型在“选择不回答”的能力上普遍表现不佳,而增加模型规模似乎并不能有效解决这一问题。换言之,单纯依赖更大、更复杂的模型架构并不能让模型学会合理拒绝回答,亟需从方法论和训练策略层面寻求突破。 令人意外的是,论文也指出那些经过专门的推理任务微调的模型,反而在拒绝回答方面的表现有所下降。尽管这类模型在数学和科学等明确领域拥有强大的推理能力,却在判断问题是否无解时遇到了困难。此发现挑战了人们对推理微调的既有认知,提示我们需要重新审视推理训练目标在培养模型不确定性认知上的有效性和局限性。 研究还发现,尽管精心设计的系统提示能够在一定程度上提升模型的拒答表现,但这并不能根本解决模型在复杂不确定场景下的推理困境。
模型的基本认知框架尚未具备高质量评估知识欠缺或问题本质缺陷的能力,表现出一定的盲目“确定性偏好”。这种现象反映了当前大型语言模型在自我反省、信息缺失判断及风险控制机制上的缺陷,暴露出进一步研究的迫切需求。 AbstentionBench的推出不仅为学术界提供了一个有力且系统化的测评工具,也为工业界推动大型语言模型的鲁棒性和安全性提供了关键参考。未来,壮大模型规模之外,更加注重模型“不确定性管理”与“拒绝回答”能力的提升,可能成为人工智能落地的必由之路。研究人员需要开发更先进的训练范式,譬如引入对“无解问题”的专门训练,提升模型的元认知能力和推理边界判断,促进其更为稳健和可信的应用。 在实际应用场景中,无论是医疗、法律,还是金融和教育领域,用户对答案的准确性和模型的诚实性有着极高期待。
一个会恰当拒绝回答的问题,比一个提供错误答案的问题更具价值和安全保障。因此,AbstentionBench不仅仅是一个评测工具,更是一种引导大型语言模型走向更安全智能未来的重要倡议。推动模型具备合理拒答的能力,将极大增强人工智能系统的用户信任度,减少错误信息的传播风险,为打造符合伦理和社会价值的智能技术奠定基础。 总结来看,AbstentionBench的研究深入揭示了大型语言模型在无解问题面前的表现不足和潜在瓶颈,强调了拒绝回答作为智能模型核心能力的必要性。未来人工智能发展需要不仅关注答案本身的准确率,也要重视模型对自身知识范围和不确定性的判断能力。通过持续完善数据集设计和训练机制,进一步提升模型拒绝回答的水平,将有助于智能系统更加安全、可靠地为人类社会服务。
AbstentionBench的发布无疑为推动这一方向的研究和实践提供了坚实基础和宝贵资源,激励学界和产业界携手攻克这一亟待突破的人机交互关键难题。