随着人工智能技术的不断发展,基于大型语言模型(LLM)的数据压缩技术受到越来越广泛的关注。传统的数据压缩方法多依赖于统计模型和手工设计的编码方案,而LLM的引入,为压缩领域带来了革命性的变革。大型语言模型通过强大的预测能力,从数据本身中自动学习复杂的统计规律,实现更加高效的压缩体现在压缩率和压缩速度上的提升。研究表明,LLM在预测下一个符号的概率分布方面表现优异,这与无损压缩中熵编码效果直接挂钩。因此,理解LLM的性能在不同参数规模和训练阶段的变化规律,对于设计和优化基于LLM的压缩系统至关重要。缩放定律作为神经语言模型领域的核心理论之一,揭示了模型性能如何随模型参数数量、训练数据量以及训练计算量以幂次定律的形式变化。
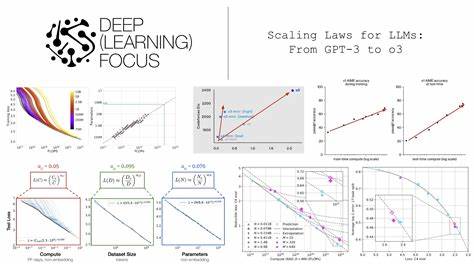
最初,这些定律被用于解释交叉熵损失的下降趋势,而该损失指标与模型预测准确性紧密相关。由于预测准确性的提高直接带来压缩性能的增强,研究人员提出探讨LLM数据压缩效果是否同样遵循类似的缩放规律。近期的实验证据支持了这一假设。选用EleutherAI推出的Pythia模型家族展开研究,其覆盖从7000万到14亿参数规模的多个模型版本。所有模型均在相同的数据集“Pile”上训练,确保对比的公正性。实验流程包括将数据(如enwik8文本数据集)拆分为固定大小的块,利用LLM预测这些块中每个字节的后续概率,然后将概率作为算术编码的先验,实现接近最优的熵编码压缩。
通过测量压缩比(压缩后比特数与原始比特数之比),能够直观评估模型在不同训练步骤与规模下的压缩效果。结果显示,随着模型参数的增加以及训练步骤的推进,压缩比明显下降,表明压缩效率提升。具体而言,不同模型和训练阶段的压缩性能可通过类似Kaplan等人提出的功率律(Kaplan-style power law)进行拟合,揭示出压缩比与模型参数规模以及训练进度之间呈幂函数关系。这些规律同样适用于非文本领域,包括图像与语音数据。尽管LLM仅通过文本预训练,其在对图像块(如ImageNet验证集上的灰度补丁)和音频信号(如LibriSpeech清洁语音)进行编码时仍展现出可观的压缩能力。说明预训练过程中模型学到的统计结构对各种字节流类型具有广泛的适用性和泛化性。
文本数据的缩放定律表现最为显著,压缩比能够随着模型和训练的扩大持续下降,达到极具竞争力的水平。非文本数据则表现出稍弱但依然明显的缩放趋势。这一现象指示了文本预训练过程中形成的“通用序列先验”(Universal Sequence Prior),使得模型能够利用语言模型中内嵌的统计特征,应对各种数据类型的冗余和模式。此外,模型的自注意力机制支持“上下文学习”(In-Context Learning),即模型能在局部上下文窗口内自动调整对输入数据的理解,捕捉其中的重复性和周期性特征,进一步提升压缩效果。该机制帮助模型在面对不同类型和内容的数据时,动态优化概率预测,从而实现更有效的压缩。这种能力反映了大型语言模型本质上不仅仅是语言工具,更是一种强大的统计学习机器。
上述发现为未来基于LLM的通用数据压缩技术发展开辟了重要方向。一方面,可以通过扩展模型参数规模及增加训练计算量,进一步提升压缩性能。另一方面,深入研究上下文学习和通用序列先验的独立贡献与协同作用,将有助于设计更高效且适应多模态输入的压缩算法。更广泛地看,这些研究也强化了大型语言模型作为一种“世间模型”(world model)的观点,即使只用文本数据训练,模型依然捕捉到广泛的自然统计规律,能够应用于视觉、语音等诸多领域。值得关注的是,当前的实验多数基于算术编码等经典控制编码方法与概率预测结合的方案,未来的压缩系统可能会探索更深层次的学习型压缩框架,结合变分方法、生成模型和端到端训练以进一步提升压缩率和应用灵活性。此外,考虑到现实应用中的计算及存储限制,对模型量化、剪枝和高效推理方案的结合研究也十分重要,有望实现高性能与低成本的最佳平衡。
研究人员还提出期待对模型内部如何逐步形成压缩能力进行追踪与分析,包括训练过程各阶段统计特征的演变、注意力模式的变化以及具体预测机制的解析。这些方向将不仅帮助提升模型压缩性能,也为理解大型语言模型的认知机制提供新的视角。综上所述,大型语言模型在数据压缩领域展现出显著潜力,且其性能遵循明确的缩放定律。结合深度学习与经典熵编码技术,LLM为无损压缩提供了一个崭新的范式。其强大的泛化能力和上下文自适应能力,使得多模态数据的压缩成为可能并且呈现出持续优化的趋势。未来,随着模型规模的扩大和算法设计的创新,基于大型语言模型的数据压缩技术有望在实际应用中得到更加广泛的推广和深化,推动信息处理效率进入全新阶段。
。