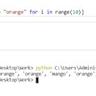
列表推导式作为Python语言中一种极为简洁且强大的工具,其优雅的语法使得遍历和筛选数据变得高效而清晰。然而,在众多开发者关注表面语法效果的同时,深入理解其背后的实现机制至关重要,尤其是在不同Python版本中推导式执行方式的迭代更新,对程序性能和作用域管理带来了深远影响。理解这些细节不仅帮助开发者编写更健壮且高效的代码,也有助于在调试复杂问题时迅速定位根因。 从概念上讲,Python列表推导式是在已有可迭代对象基础上,通过简洁的表达式完成数据的遍历与转换操作,例如[x for x in range(5)]生成了一个包含0至4的列表。早期Python版本(如3.10)在执行此类语句时,会隐式地创建一个新的函数框架,这一隐藏函数称为"<listcomp>"。通过Python的字节码反汇编工具dis模块可以清晰地看出这一过程:主程序模块加载和构造出隐藏的推导式函数代码对象,随后调用这个函数,将外部生成的迭代器传入。
这个内部函数负责迭代数据并将结果依次追加到一个列表对象。 在实际上,这意味着列表推导式执行时会在一个独立的局部作用域内运行。这种设计的优点是作用域清晰且互相隔离,可以避免外部变量名的冲突和污染。但同时,这也引入了局限性,特别是在执行诸如exec动态代码时,列表推导式内部无法直接访问外部函数的局部变量,从而导致NameError等作用域无法访问的异常。这一点在某些面向动态代码执行的场景中可能成为阻碍。 Python 3.12引入了PEP 709,革新了列表推导式的实现方式。
新版本不再为每个列表推导式创建单独的函数体,而是将其内联嵌入调用栈所在的函数中。这种"内联推导式"技术使得整个列表生成过程在同一作用域框架内执行,使得列表推导式内能直接访问外围函数的局部变量。底层字节码使用了LOAD_FAST_AND_CLEAR、SWAP以及END_FOR等新的指令序列,高效地管理了变量的临时移位和恢复,避免了作用域混淆和变量覆盖问题。 这一变化不仅提升了执行效率,减少栈帧切换开销,也在动态代码执行时带来了更好的兼容性,像exec语句便可以顺利访问外层作用域变量,避免了因作用域隔离导致的错误。对于开发者而言,这意味着代码在不同Python版本间迁移时,尤其涉及到动态执行和闭包变量访问的场景,行为会有所不同,需特别留意版本兼容性问题。 在技术细节层面,Python虚拟机(CPython)是一个基于栈的执行环境,诸如LOAD_FAST、LOAD_CONST等指令负责将数据压栈,而BINARY_ADD、CALL_FUNCTION等则是从栈顶弹出操作数执行运算或函数调用,后将结果再次压栈。
旧版列表推导式通过MAKE_FUNCTION生成新的函数对象,再调用该函数完成列表构造;新版通过优化的调用约定和新指令集,不再拆分调用堆栈,实现了无缝内联循环与列表追加。 这种演进体现了Python开发团队对语言运行效率及语法表现力的不断追求。推导式由隐藏的函数封装变为内联执行,既保留了Python清晰简洁的编码风格,也改善了性能瓶颈,尤其是在大量数据迭代处理时效果显著。同时,这也体现了语言底层实现对高阶语法糖的优化升级,使开发者得以享受更快速响应和更少隐式错误的开发体验。 此外,对于传统版本Python 3.10及之前,若需要规避推导式局部作用域带来的限制,有技巧地通过exec函数指定locals或globals字典参数,可以将外部的实际变量映射到推导式作用域,确保动态执行的语法树能够正确访问外围变量,这需要一定的元编程经验与对作用域链的深入理解。对于工程实践而言,合理利用这一技巧或升级至支持内联推导式的新版本,能有效提升代码鲁棒性及动态执行灵活性。
总的来看,Python列表推导式的实现从函数闭包隔离到内联优化,反映了语言设计不断进步并紧贴现代开发需求的趋势。掌握其底层执行流程及版本差异,有助于更有效地使用推导式发挥Python的强大表达力,同时规避潜在的作用域与性能陷阱。未来随着Python解释器的进一步发展,我们有理由期待更多语法糖与执行引擎的协同优化,为开发者提供既优雅又高效的编程体验。 。