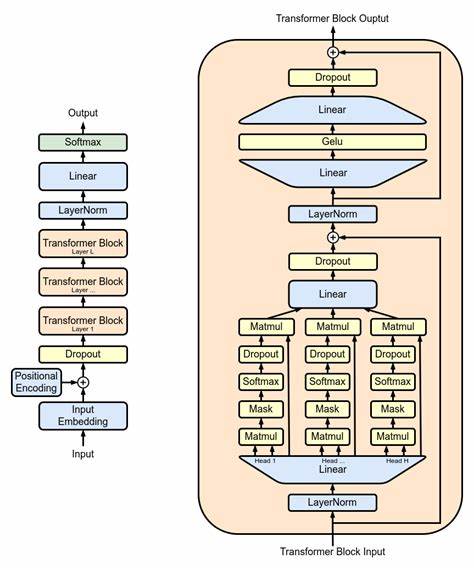
随着人工智能技术的飞速发展,基于Transformer架构的大型语言模型,尤其是GPT(Generative Pre-trained Transformer)系列,已经成为自然语言处理领域的热门模型。这些模型参数规模庞大,计算资源需求极高,如何提升推理效率成为了学术界和工业界关注的焦点。批处理(batching)作为机器学习推理中常见的技术,能够显著提高推理吞吐量,但对于GPT这类存在自回归特性的模型,批处理的效果及挑战仍需深入剖析。 从基础结构出发,GPT模型由多个Transformer块堆叠组成,每个Transformer块包含了密集层投影、自注意力机制(self-attention)以及前馈网络(feed-forward network,简称FFN)。推理的过程可以划分为初始阶段和自回归阶段。初始阶段处理输入的提示语,生成第一个输出和相关的关键值缓存(KV Cache);自回归阶段走token级别递推,通过利用之前生成的token及KV缓存,逐步预测后续token。
考虑到计算复杂度和内存瓶颈,分析GPT中矩阵乘法所消耗的浮点运算数量(FLOPs)和内存输入输出(I/O)是理解批处理效果的切入点。以一个Transformer块为例,自注意力部分的参数量约占总参数的四分之一,而前馈网络部分(含输出投影)则约占四分之三。自注意力的计算和内存使用随着序列长度的平方增长,这使得长上下文场景的推理变得尤为耗费资源。KV缓存的存储是另一大内存负担,例如在6.7亿参数模型中,32层的KV缓存占用高达8GB内存。 从时间复杂度来看,初始阶段的计算量被序列长度平方项和隐藏维度平方项共同主导;而在自回归阶段,计算复杂度随着序列长度线性增加且受到隐藏维度平方项影响较大。此外,Transformer中的矩阵乘法分为两类:一类是前馈网络中的密集层矩阵乘法,其可以通过批处理以提升计算效率;另一类是自注意力机制中QK^T的矩阵乘法,批处理在这类计算中对计算强度无明显提升,因为批量增加了计算和I/O,使得算术强度(FLOP:I/O比)保持不变。
在初始阶段,输入序列因序列长度较长,自带批处理效果,特别是在前馈网络的计算中表现出较高效率,而自注意力部分受制于其计算结构,批处理效果有限。自回归阶段的前馈网络输入形状通常为(batch_size,1,h),此时批处理能够显著提升计算效率,因为矩阵乘法中隐藏维度较大,且序列长度为1;相反,自注意力机制仍然难以从批处理中获益明显。 通过微基准测试,我们可验证上述理论分析。实测结果显示,无论模型规模大小,初始阶段的前馈网络会因为序列长度已较长而批处理收益减弱;而自回归阶段前馈网络的批处理效率几乎没有上限,提升效果极其显著。自注意力部分批处理在短序列的初始阶段表现出一定效益,但随着序列长度增大,批处理收益趋近于零。 具体的微基准测试以NVIDIA A100 GPU和PyTorch2.0为平台,涵盖多种模型隐藏维度、序列长度及批量大小组合。
整体趋势表明,批处理显著提高了模型推理的吞吐量,特别是在自回归阶段的前馈网络计算中实现了几乎线性增效。同时,批处理带来的延迟损失不明显,即使批量达到128,平均延迟仍保持较低水平,实现了批处理的"免费午餐"。 自注意力部分由于其特殊的矩阵乘法结构,延迟随着批量线性增加。这是因为该部分的算术强度无法通过批处理提升,且每个额外的batch都引入了新的计算和内存访问。但在初始阶段,对于较短序列,批处理仍有一定的速度提升空间,这可能与底层张量核优化和计算单元利用率有关。 采用Roofline模型能够进一步厘清批处理带来的性能变化。
该模型将算术强度与对应的理论硬件峰值算力联系起来,揭示了不同计算类型受计算还是内存带宽限制。测试数据清晰表明,初始阶段前馈网络计算受GPU峰值算力约束,而自回归阶段前馈网络受内存带宽束缚;自注意力的性能在批处理中未出现算术强度提升,实测算力增益部分源于软硬件协同优化不完善。 从用户体验角度看,文本生成的端到端延迟主要由自回归阶段主导,尽管初始阶段延迟较低,但生成数百甚至上千token时延迟积累明显。批处理技术在自回归阶段展现出巨大价值,合适批量使得整体吞吐量显著提升,延迟仅略有上升。例如,批大小为2时,延迟基本持平但吞吐量倍增;批大小为4时,延迟增加约14%,吞吐量提升达3.5倍,表明性能成长具备明显的边际效应递减特征。 模型推理服务端优化方面,结合批处理的实践提出了两大策略。
第一是融合自注意力计算,尤其是针对QK^T乘积与Softmax操作的内核融合,如借鉴FlashAttention技术,减少临时内存占用和中间数据传输,提升执行效率。第二是跨请求批处理,将多个请求的前馈网络输入堆叠成大矩阵批量处理,然后再拆分执行自注意力操作,解决了序列长度不一带来的实际难题。这些优化方案有效平衡了性能提升与延迟增量。 总结而言,GPT推理中的批处理效应表现出复杂多面性。批处理能够显著提升前馈网络部分的计算吞吐量,尤其是在自回归阶段,对于提升服务端推理性能至关重要。自注意力部分则对批处理的响应有限,主要受限于内存访问模式和计算结构。
综合运用软硬件协同优化和巧妙的算法设计,可以最大化利用批处理的优势,从而推动大规模语言模型的实际应用与推广。未来随着硬件技术的发展和深度学习推理框架的优化,批处理在LLM推理中的策略与方法将更为多样与高效,值得业界持续关注和研究。 。