近年来,人工智能技术飞速发展,尤其是生成式模型在自然语言处理、计算机视觉和机器人学等多个领域发挥了重要作用。传统上,自回归模型以其良好的性能和计算效率成为主流选择,特别是在数据充裕的环境下表现卓越。然而,随着训练数据逐渐趋于饱和,计算资源相对充裕但有效训练数据有限的现实状况日益显著,生成模型如何在数据受限环境中保持竞争力成为亟需研究的问题。近期一项突破性的研究揭示了扩散模型在数据受限场景下取得的优异表现,展示了其在深度学习领域开辟新方向的潜能。过去十年,深度学习的发展主要依靠计算能力和数据规模的双重提升。以GPT系列语言模型为例,从GPT-1到GPT-5通过不断扩大模型规模和丰富数据集实现了性能跨越。
然而,专家们普遍担忧这条增数据、增计算的路径不具备无穷延续性。数据增长速度远低于计算能力的提升,造成训练数据成为深度学习扩展的瓶颈。著名研究者伊利亚·苏茨克维尔在2024年NeurIPS测试时间奖演讲中指出数据并未像计算力那样呈现爆炸式增长,互联网作为数据来源的有限性限制了未来模型的训练条件。Epoch AI的系统分析进一步指出,预计到2028年,计算资源将远远超过可用的训练数据总量,标志着人工智能研究将正式进入数据受限阶段。对于研究者和开发者而言,如何利用有限数据进行高效训练尤为关键。本文所述研究聚焦于比较两大主流生成模型范式 - - 自回归模型与扩散模型 - - 在数据受限条件下的表现。
自回归模型自2019年GPT-2论文推广以来,因其简单且高效的左到右序列建模方式占据语言模型主导地位;扩散模型则在计算机视觉领域掀起革命,自2020年DDPM论文问世后广受关注,通过逐步将噪声注入数据再反向恢复,提高了生成样本的多样性与质量。尽管两者目标一致,均旨在最大化联合概率分布,但在因式分解方式及训练机制上存在根本差异。近年来,语言领域开始尝试将扩散模型应用于文本生成,例如通过随机掩码的离散扩散模型和先将词元投影到嵌入空间再加噪声的连续扩散模型。与此同时,视觉领域也在探索使用自回归方法生成图像,例如PARTI和DALLE系列模型。该跨领域的尝试反映了研究社区对生成模型未来方向的深刻思考。然而,在机器人学等更多领域,不同范式的并行应用产生了混乱和不确定,使得是否优先选择扩散或自回归模型成为急需解答的核心问题。
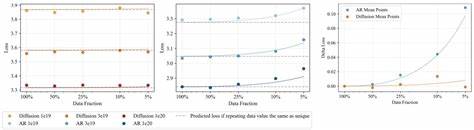
研究团队在大量实验基础上系统评估了两种模型在数据受限环境下的性能变化。他们发现,在较低计算预算下,自回归模型表现优异,训练速度快,验证损失较低。然而,随着训练计算预算的增加,特别是通过多轮迭代训练(即多周期训练),扩散模型表现出持续性能提升,最终在关键计算点后整体优于自回归模型。值得注意的是,自回归模型更易出现过拟合现象,随着训练轮数增加,其性能趋于平稳甚至下降;扩散模型则展现出极强的训练稳定性,经过比自回归多10倍以上的训练周期依然未见过拟合迹象。更重要的是,扩散模型对数据重复的适应性明显优于自回归模型。他们以相同计算预算、不同数据唯一性比例进行对比,发现自回归模型在重复数据多时验证误差显著上升,表明其过拟合加剧;而扩散模型无论数据重复多少,性能保持稳定,显示出极强的泛化能力。
这种强鲁棒性为有限数据环境下的模型训练带来了突破。研究中还提出了"数据重用半衰期"概念,衡量数据重复利用中效果衰减的速度。扩散模型的数据重用半衰期约为500,即在数据重复训练多达数百次后仍能有效利用数据;而自回归模型该值仅约15,说明其对重复数据敏感度更高,利用率迅速下降。该发现标志着扩散模型在稀缺数据情形下可实现远超传统方法的数据扩充效果。进一步分析显示,扩散模型通过多样化的掩码策略,隐式地实现了对训练数据的增强,等同于从不同角度、顺序进行条件预测,丰富了模型学习任务,提升了数据效率。相比之下,自回归模型则局限于单一路径的左到右序列建模,数据利用角度单一。
对此,研究者利用显式数据增强方法对自回归模型进行训练,增加了多种令牌排序,实验结果证明这种多顺序训练能够显著降低验证误差并延缓过拟合,部分消除了两者之间效率差距。该洞见为生成模型范式之间建立连续体提供了理论基础,即通过调整训练任务的多样性和复杂度,可以在计算效率与数据效率之间寻求最佳平衡。最后,通过下游语言理解任务验证,扩散模型在相同数据预算下普遍优于自回归模型,表明其验证损失的提升有效转化为实际应用性能的提升。上述发现不仅仅局限于语言模型领域,未来随着机器人学、医疗健康等多个序列建模领域面对数据采集难题,扩散模型的数据扩增优势或将成为广泛采用的主流方法。总结而言,随着高质量数据资源增长放缓,提升数据使用效率成为深度学习模型扩展的关键瓶颈。最新研究证实,在数据有限但可用计算资源充足的情形下,扩散模型展现出显著的优势,这一结论有别于此前普遍认为自回归模型性能更佳的传统观点。
面向未来,科学家和工程师应根据实际资源配置合理选择生成模型范式。尤其在医疗、法律等数据隐私和稀缺性极为突出领域,扩散模型的优势值得重点关注。随着合成数据技术的发展,结合扩散与自回归模型的混合训练方法,或将开辟生成模型新纪元。通过持续的理论探索与实证研究,生成模型将在有限数据环境中实现更强更优的性能,推动人工智能应用迈向更广阔的未来。 。