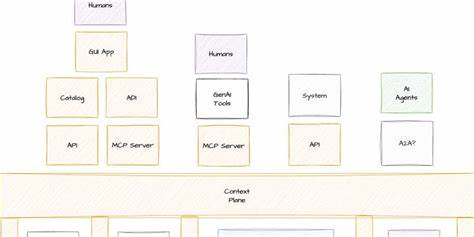
在当今数据驱动的时代,如何高效组织、理解和应用信息成为企业和技术发展的核心挑战。随着人工智能技术的快速演进,"上下文层"(Context Plane)作为一种新兴的数据架构理念,正逐步成为整合各种数据及其元信息的关键枢纽,赋能智能代理更准确地理解业务需求和决策逻辑。本文将基于Shagility的思考,全面解构"上下文层"的内涵、构成以及其对未来AI数据栈的深远影响,帮助读者建立系统性认知并洞察行业趋势。"上下文层"的概念是围绕着构建一个统一、贯穿数据及其相关元信息的平台展开的,目的是为支撑智能代理(AI Agents)以及复杂业务流程提供清晰、精准且全方位的语义环境。这种语义环境不仅包含对核心业务概念的定义,还涵盖数据模型、规则契约、统计特性、逻辑转换、指标计算、业务问题及对应行动方案等多层次要素,从而实现数据从原始呈现到价值创造的完整闭环。作为一个富有经验的数据从业者,Shagility强调"上下文层"不是简单的数据储存空间,而是信息的有机整合体。
这个层级涉及的数据模式涵盖但不限于企业术语(Business Glossary)、核心业务概念(Core Business Concepts)、核心业务流程(Core Business Processes)、概念关系(Conceptual Relationships)、详细属性(Details)、字段元数据(Field Metadata)、物理结构(Physical Structures)、数据规则与期望(Data Rules and Expectations)等多个方面。每个部分都与其他部分相辅相成,构建出能够承载复杂查询和智能推理的语义网络。其中,企业术语是标准化内部沟通的语言基础,为组织内不同角色间提供统一词汇,减小歧义风险。核心业务概念则指向企业管理和计量的实体,如客户、产品、订单等,这些实体是数据设计的基石。业务流程描绘实体间的交互和时间演变,反映业务事件和生命周期的动态变化。概念关系则抽象呈现这些实体及其交互构成的整体逻辑框架,强调平台无关的模型表达。
在详细层面,具体属性及字段信息为核心业务实体赋予个性化内容,包括名称、状态、日期等,强化数据的描述力和可操作性。物理结构则指明存储实现细节,比如表结构、字段数据类型及索引机制,使逻辑模型可落地为系统性能优化的技术方案。数据规则和期望则强调数据交换契约的存在,比如格式、有效性、时效性设置,保证数据在流通和处理过程中的质量与一致性。除数据定义与结构内容外,"上下文层"还纳入了统计特性(Data Profiles),即对数据分布、唯一性、缺失率等指标的监测,为可信赖分析提供支撑。转换逻辑(Transformation Logic)则解答如何将原始、分散的数据整合转换成可用、可靠的信息单元,体现业务规则和操作的自动化实现。原始数值(Raw Numerical Values)和汇总数据(Aggregated Values)分别承担数据基础和高阶计算的职能,保障统计与分析的多层次实现。
派生指标(Derived Metrics)更进一步,通过综合计算支持业务洞察与绩效衡量。业务问题(Business Questions)映射了决策层面对不同数据及指标的需求,是上下文层对外重要的连接点。针对特定问题产生的各种决策、操作即为行动(Actions),两者串联起数据洞察与实际业务执行。最终,信息应用(Information Apps)作为数据交互的界面载体,将深层含义和洞察以可视化、接口或报表形式传递给用户,实现数据价值的有效释放。"上下文层"的另一个重要特点是其高度的跨界融合和概念交叉。传统数据领域的界限往往导致模块孤立,难以形成整体视角。
Shagility反复强调拆解重组,将看似重叠的组件,分解为最小、唯一且互不重叠的数据基础元素,从而构建原子级别的语义单位。通过这种方式,系统能够消解过往架构中的碎片化与重复定义,提高信息的关联性及智能代理的理解精准度。在实践层面,Shagility也提示"上下文层"建设的过程并非一蹴而就,而是一个写作与思考并行、持续迭代的认知过程。它要求从库房科学与信息科学等领域吸收更有深度的元数据管理理念,结合现实用例不断完善体系,充分兼顾具体技术实现与抽象模式的结合。跨领域专家协作和以AI本身的需求为引导,成为未来"上下文层"进化的重要方向。面对复杂的问题,Shagility引用了"数据过去之幽灵"的隐喻,体现了历史数据模式对当代架构设计的深刻影响。
与此同时,保持清晰的边界感又显得难以实现,各数据组成或职能模块间时常出现交叉,因此仅凭传统数据架构设计语言已无法满足现阶段智能数据栈的需求。他建议拆解问题、抽象语义原子单元以及聚焦具体的AI应用场景,寻找最为直接且务实的路径。进一步来看,"上下文层"不仅是静态的数据模型和规则集合,它更塑造了一种动态的知识管理机制,为AI智能代理提供上下文感知和推理环境。通过整合多层级、多维度的业务知识及数据描述,它优化了信息的语义理解,降低了业务复杂性和语义歧义,使智能系统能够更有效地实现自动化决策和精细化服务。在数据驱动创新浪潮中,"上下文层"已被视为激活企业数据资产潜力的关键支柱。它带来了看似琐碎却至关重要的数据治理规范,促进了数据资产的透明化和可追溯性,推动业务洞察的系统化和规范化。
同时,良好的"上下文层"定义让数据科学家、业务分析师以及AI开发者都能从同一语义基础出发,极大提升团队协作效率和整体成果质量。值得关注的是,Shagility的观点体现了一种兼容多样数据语言和模式的开放态度。面对不断演进的数据工具和技术生态,放弃固化的边界思想,拥抱多样并存与动态调整,才是构建未来AI数据栈的必经之路。这一理念突破了传统单一维度数据管理的局限,使得"上下文层"不仅是技术架构,更是一种面向未来信息管理的哲学思考。总而言之,"上下文层"作为AI数据栈的核心组件,其重要作用日益凸显。它不仅承载着组织内部所有核心业务概念及其关系,更融合了数据模型、业务逻辑、性能规则及实际应用场景,把复杂异构数据转化成可操作、智能化的信息资产。
对此层的深入理解和有效构建,是驱动智能时代企业数字跃迁和技术飞跃的关键所在。展望未来,随着人工智能不断渗透于各行各业,"上下文层"必将成为链接业务与智能的桥梁,助力构建更智慧、更敏捷的数字生态系统。 。