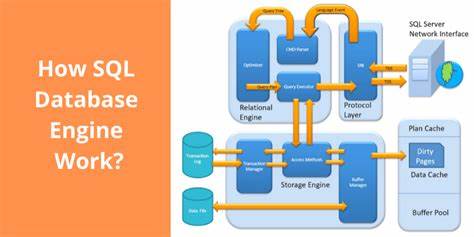
SQL引擎作为数据库系统中承上启下的核心组件,承担着客户端和存储层之间的桥梁职责。它的主要任务是将用户发送的SQL查询语句,经过复杂的内部处理,转化为对数据的有效操作,从而保证数据访问的准确性和高效性。了解一个SQL引擎的内部运作流程,对于数据库开发者、运维工程师及数据分析人员而言,都是提升数据库调优和应用性能的关键。本文将从SQL引擎的多个关键阶段出发,详尽解析SQL查询在执行过程中的生命周期,结合开源项目Dolt的go-mysql-server(GMS)实现,深度揭示SQL引擎的工作细节和优化策略。 首先,SQL引擎面对用户提交的查询时,会开始解析过程。解析阶段的核心任务是把输入的SQL字符串转换为抽象语法树(AST),这是数据库理解和操作查询的基础。
解析器通过分词,将字节流切分成固定结构的词法单元(Token),再运用递归语法规则逐步构建AST节点。解析方式有左递归和右递归两种,左递归方法更节省内存,但逻辑更复杂,Dolt采用了基于Yacc的左递归解析器。这种解析器的设计让引擎能够快速而准确地捕捉查询语句结构,及时反馈语法错误,保障输入的规范性。 解析成功后,SQL引擎进入绑定阶段。此时引擎要将语法树中的标识符与数据库的实际对象进行匹配,包括表名、列名和别名的解析与作用域限定。绑定流程类似于编程语言中的变量定义与引用,确保查询语句能正确访问指定的数据对象,同时做类型检查和上下文关联。
比如当查询中涉及多表连接时,列名歧义需通过表别名化解,子查询和公共表表达式(CTE)也需在对应作用域内正确绑定。绑定结束后,会生成更贴合执行的计划节点,作为后续优化和执行的基础。 紧接着是计划简化阶段,数据库会将复杂多样的SQL表达式用一套规范化的中间表示(IR)来重构。这个步骤旨在规范查询结构,提升逻辑表达式的一致性,方便后续优化。计划简化常见于过滤条件的提前下推、列裁剪等操作,减少无谓的数据遍历和计算。特别是在处理子查询和联结时,计划简化会尝试将复杂的子查询转化为等价的连接操作,利于统一优化和降低执行成本。
正是计划简化为下一步连接顺序的探索计划铺平道路。连接探索是SQL优化器中决定执行效率的关键环节,涉及如何在多张表之间选择最佳连接顺序和连接方法。不同的连接策略如哈希连接、归并连接和索引查找连接在不同数据分布和表大小条件下表现差异明显。Dolt的GMS使用动态规划算法系统性地枚举所有合法的连接顺序组合,利用记忆化结构(Memo)缓存中间计算结果,避免重复工作。这个递归合并的逻辑组表示法,可以高效地储存和管理大量状态空间,将最优的执行路径筛选出来。 效率的最直接体现则来自连接成本估算环节,连接顺序探索完成后,优化器要对候选计划进行细致的成本分析。
成本模型不仅考虑到逻辑操作的数量,还会模拟存储I/O、内存消耗和CPU计算等多维度因素。Dolt通过收集确定性的统计信息和基于直方图的键分布估计来进行精准的估算,能够动态调整连接策略以适应不同场景。比如小规模结果集可能更适合索引查找连接,而大规模数据则更适合哈希连接,优化器借此选择最经济的执行方案。 经过一系列的搜索与评价步骤,优化器最终确定了物理执行计划。接下来的执行阶段,SQL引擎将计划节点组装成一颗火山迭代器(Volcano Iterator)树,各执行节点通过迭代接口逐层处理数据,实现数据流的拉动式传递。这种设计支持灵活的算子组合和延迟求值,提高运行时的资源利用率。
执行过程中,复杂的操作如GROUP BY、聚合函数等可能采用缓冲机制实现批量聚合,保证结果的完整性与准确性。Dolt的执行器已结合自定义的迭代器来适配键值存储层,确保从逻辑计划到物理存储的无缝转换。 执行完成后,查询结果会通过“刷盘”操作转换为客户端可识别的格式。由于存储层、执行层以及网络传输层在数据表示形式上各不相同,SQL引擎必须保证数据在各种格式间的高效转换。例如,Dolt的KV层使用字节数组的键值对存储,执行层则采用Go语言内存中的原生数据结构,最后通过MySQL协议转成字符串传输给客户端。通过批量处理和缓冲重用技术,SQL引擎不仅降低了内存压力,也提升了数据吞吐量。
当前SQL引擎仍面临诸多挑战与发展方向。诸如统一中间表示的标准化,有助于简化各阶段间的接口和信息传递,减少内存使用和代码复杂度。内存管理依然是性能瓶颈的重点,尤其在Go语言环境下,避免频繁堆分配和提升缓冲区复用能明显优化执行效率。此外,支持分布式计算、多线程并行以及矢量化执行策略,是提升现代数据库应对大规模数据处理能力的必经之路。 综上所述,SQL引擎作为数据库系统中至关重要的逻辑层,结构复杂且环环相扣。从查询解析、绑定、计划简化、连接顺序探索、成本估算直到执行与结果返回,每一步都蕴含深厚的计算机科学理论与工程实践经验。
借鉴如Dolt这类开源项目的案例,不仅让我们洞悉了SQL引擎的设计哲学,还能为数据库系统的优化与创新提供实用参考。未来随着数据规模与复杂度的持续增长,进一步提升引擎的灵活性、扩展性与性能将成为数据库研发的重要方向。深入理解SQL引擎的内部机制,不仅助力开发和调优高效的数据库服务,也为数据驱动的应用赋能,推动数字经济迈向新的高度。