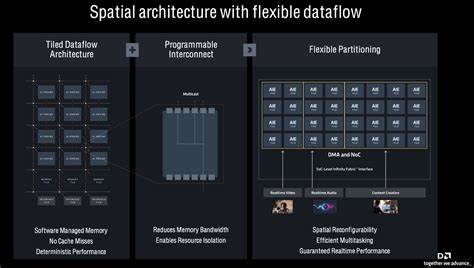
随着计算架构的不断演进,传统的指令顺序执行模型已无法充分发挥现代硬件的并行性能。空间数据流架构(Spatial Dataflow Architectures,简称SDA)作为一种新兴的计算模型,通过将程序表示为数据流图(Dataflow Graph, DFG),以无全局指令顺序的方式实现高效并行计算,成为推动高性能计算发展的重要方向。然而,这种架构的独特执行机制也对编程语言和工具链提出了全新的挑战。Ripple作为一款专门针对空间数据流架构设计的编程语言扩展,正是在此背景下诞生,旨在为开发者提供更贴合SDA模型的编程范式,加速软件与硬件的协同优化。空间数据流架构的核心思想是将程序转换为数据流图,其节点表示具体的指令,边则明确指示指令间的通信关系。在这种模型中,不存在传统意义上的程序计数器,也就是说,指令没有固定的执行顺序,而是以"数据就绪即触发执行"为原则,充分利用数据间的依赖关系实现高度并行。
诸如TRIPS、WaveScalar、EDGE、CGRA及AI Engine等项目都体现了这一设计理念。面对这样一个颠覆传统计算模型的架构,Ripple的出现将开发焦点从尝试直接编译传统C代码转向主动将SDA的核心特性暴露给程序员,使其能够在语言层面直接操控并行和异步行为。Ripple通过引入异步迭代器(async iterators)这一编程结构,为程序异步执行提供了简洁灵活的表达方式。与传统函数调用不同,异步迭代器不需等待函数体完成,其调用方仅需将参数放入由async定义的隐式输入队列,调用即被视为"触发事件",整个函数体在后台异步运行。此外,异步迭代器支持递归调用,允许函数在执行过程中再次向自身传递参数,形成复杂的异步执行链路。async关键字为Ripple程序提供了独具特色的异步非阻塞操作机制。
在一些场景下,程序员可结合ind关键词为异步迭代器赋予流水线式并行语义,即多个异步调用无需严格顺序完成便可并发运行。这种设计极大提升了程序的并行度和吞吐能力,使得多任务执行不仅可能,而且高效。与之相对,如果没有ind标记,async迭代器则表现为单线程执行,确保执行顺序和状态一致性。Ripple在同步原语方面的设计亦令人关注,其采用atomic构造实现了任务之间的同步与内存访问冲突检测。编译器静态分析atomic操作所读写的地址集合,保证多个atomic块在无地址冲突时可实现并行执行,达到较高的同步效率。该机制有效避免了传统锁的复杂竞争,提升了系统的整体性能稳定性。
为了具体说明Ripple的使用效能,论文用广度优先搜索(Breadth First Search,BFS)作为示范方法。在Ripple代码中,初始化函数和搜索函数均使用async声明,调用方无需阻塞等待,大量异步任务得以同时展开。特别是递归"调用"通过显式push操作实现,强化了"发送即可忘记"的异步特性。在BFS实现中利用atomic块定义局部变量,允许多个异步任务间在原子操作中安全更新状态,同时维持高度并行处理,体现了Ripple并行设计的先进水平。此外Ripple配套了完整的系统堆栈支持,包括指令集架构(ISA)、专用编译器及硬件微架构设计,使得Ripple程序能够无缝映射至底层硬件执行。此协同设计极大提升了硬件利用率与程序运行效率,进而推动了异步数据流计算模式的实际落地和商业应用。
在性能方面,Ripple相较于之前的Riptide项目展现显著优势。Riptide主要针对不改动原有代码的自动编译,而Ripple则通过新语言特性主动暴露硬件并行模型,充分利用潜在硬件资源,获得更优的性能表现。从性能指标和利用率角度来看,Ripple的设计更契合未来高性能计算和人工智能计算的需求。尽管Ripple表现优秀,但其仍存在各种前沿挑战。当前实现中,基于C语言的平坦地址空间无法充分支持大型应用程序,如何虚拟化有限SDA资源以执行超过硬件容量的数据流图,仍是未完全解决的问题。同时,引入分段地址空间可能带来更强的可扩展性和资源管理能力,未来可能成为突破口。
另外,Ripple与高层次综合(HLS)技术存在一定交叉,但二者侧重点有别。Ripple偏向语言级别设计与数据流并行抽象,Kanagawa等项目则专注于从语言到门级逻辑的综合,二者相辅相成,可望共同推动空间数据流架构产业生态完整发展。值得注意的是,Ripple中的atomic原语与硬件描述语言蓝图(Bluespec)中的规则机制有相似之处,但Ripple编译效率更优且运行时性能更确定,弥补了后者在复杂依赖跟踪时的瓶颈。综上所述,Ripple为异步编程在空间数据流架构领域提供了一种创新路径,兼顾易用性与性能,颠覆了传统编程范式。它不仅为程序员带来了更灵活的并行控制能力,也推动了编译器设计、硬件架构乃至系统软件的协同革新。随着异构计算与人工智能技术的快速发展,Ripple的理念及实现有望在未来大规模并行计算场景中发挥关键作用。
未来的研究将侧重于支持更大规模应用、优化内存管理模型及进一步提升编译器智能化水平,从而实现真正高效、可扩展并且易用的空间数据流编程生态。 。