在人工智能迅猛发展的时代,语言模型正以前所未有的速度更新换代。长猫闪电(LongCat-Flash)作为目前技术领域的一颗耀眼新星,以其5600亿参数规模和创新的多专家(Mixture-of-Experts,MoE)架构,引领了语言模型效率与性能并重的发展方向。它不仅突破了计算资源的瓶颈,更为复杂任务的智能处理奠定了坚实基础。长猫闪电的诞生标志着语言模型在规模与智能之间的平衡达到了新的高度。长猫闪电的核心创新,在于其灵活且高效的动态计算机制。传统的巨大语言模型往往需要激活全部参数,导致计算冗余和资源浪费。
而长猫闪电巧妙地设计了零计算专家机制,根据输入上下文的不同,智能激活介于186亿至313亿之间的参数,平均约270亿参数参与计算。这种依照重要性分配计算资源的方式,不仅极大地提升了推理速度,还有效降低了推理成本,确保模型在保持强大表达能力的同时,具备高效的实际应用能力。为了进一步优化模型的训练和推理流程,长猫闪电引入了短路连接的多专家设计(Shortcut-connected MoE,ScMoE),扩展了计算与通信的重叠窗口,克服了海量专家模型在多设备并行训练中常见的通信瓶颈问题。通过这一设计,长猫闪电成功实现了在数万个加速器上稳定训练,并在推理阶段达到超过每秒100个标记(Tokens Per Second,TPS)的高吞吐量和低延迟表现,这对于实时交互和大规模部署至关重要。大规模模型的训练稳定性一直是行业痛点,而长猫闪电通过多层面策略保证了训练过程的稳健性和可重现性。模型采用了基于理论保障的小规模代理模型的超参数迁移策略,从而大幅度缩短了寻找最佳参数配置的时间。
此外,其模型增长机制利用了半规模预训练检查点,提高了初始化效率和模型表现。训练过程中,长猫闪电融合了路由器梯度平衡、隐藏层激活抑制(z-loss)及针对性优化器调优等技术,有效缓解了训练震荡和激活爆炸的风险,确保长时间训练不出现不可逆损失峰值。同时,模型引入确定性计算保证了实验高度可复现,可及时检测并防范训练过程中的静默数据错误,进一步增强大型集群训练的可靠性。长猫闪电除了具备庞大规模和高效架构,还重点聚焦智能代理能力的培养。其训练流程分为多阶段,首先将预训练数据融合的两阶段策略导入模型,进一步强化其在推理密集领域的表现。中期训练阶段在提升推理与代码能力的同时,将上下文长度扩展至128k标记,满足更复杂交互的需要。
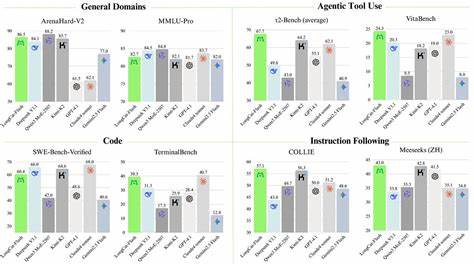
后期训练基于高级基础模型,应用多代理合成框架,设计涵盖信息处理、工具复杂度与用户交互三个维度的任务难度,打造具备多样场景适应能力的代理智能。面对高难度问题的匮乏,通过特殊控制器生成需要多步骤推理和环境交互的复杂任务,赋予模型更为深厚的自主思考和应变能力。在各类公开基准评测中,长猫闪电展现了全面而均衡的实力。无论是常规的多语言理解评测MMLU、推理基准ArenaHard,还是数学推理MATH500和代码生成Humaneval+,长猫闪电均表现出不俗的竞争力,尤其在多项agentic任务和复杂工具调用上取得领先成绩。其通过动态激活机制精准分配计算资源,使模型在保证性能的同时实现运输效率和成本的平衡,成为当前大型多专家模型中的典范。长猫闪电的开放与易用也为开发者提供了便利。
它已集成于多款平台和推理框架,支持工具调用格式规范,方便实现外部API和工具链的联动。官方发布了详细的部署指南和示例聊天模板,赋予用户多轮对话和复杂指令处理能力,极大地降低了大语言模型在实际应用中的技术门槛。作为开放源代码且基于MIT协议发布的项目,长猫闪电不仅在学术界引发广泛关注,也促进了产业界的技术革新。它呼应了当前AI行业对高性能、大规模、低成本智能系统的迫切需求,也为后续更具智能化、适应性的语言模型研究提供了宝贵经验与实践基础。总的来说,长猫闪电凭借其创新的多专家架构与动态计算机制、稳健高效的规模训练体系以及针对智能代理任务的多阶段训练方案,成为当前及未来AI生成式模型中的里程碑。它的设计理念和技术实现极大推动了大语言模型的应用边界,从科研探索到真实业务场景均展现出广阔的应用前景。
在人工智能语言理解和生成的生态中,长猫闪电无疑为行业注入了新的活力,其未来发展值得持续关注。随着技术的不断更新迭代,期待长猫闪电进一步突破,助力智能技术进入更高效、更智能的新时代。 。