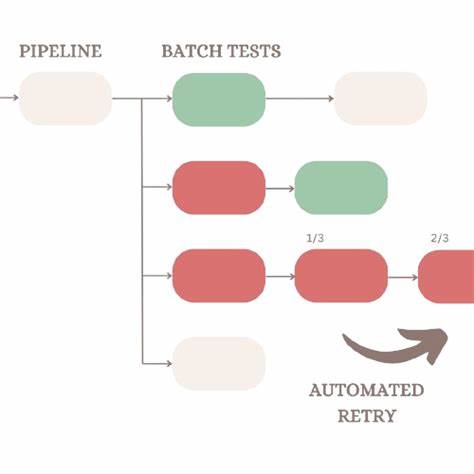
在现代软件开发流程中,自动化测试成为保障软件质量的关键环节。随着测试套件规模不断扩大,测试的稳定性和准确性日益受到关注。自动重试(Automated Retries)机制作为一种辅助技术,旨在针对测试失败的用例自动重新执行,以期减少偶发性错误带来的影响。然而,围绕自动重试的讨论一直存在较大分歧:它究竟是提升测试效率的有力工具,还是掩盖潜在问题的"反模式"?本文将深入剖析自动重试机制的核心原理、利弊表现和实战应用,为测试从业者揭示全面而客观的视角。自动重试机制的工作原理相对简单明确。一般的自动化测试框架在执行测试用例时,每个用例只运行一次,结果被记录为"通过"或"失败"。
而加入自动重试功能后,当测试用例第一次执行失败时,框架会立即或稍后自动触发该用例的再次执行,重试次数通常可由配置参数决定。最终的测试报告除了展示用例整体的最终状态,还会额外呈现某一用例多轮执行的成功率,辅助团队对失败模式进行深入分析。令人警惕的是,自动重试机制极易被误用,导致负面效果尤为突出。当团队在面对一批纷繁复杂、经常出现间歇性失败(俗称"测试不稳定"或"flaky tests")时,自动重试有时被视作"快捷解决方案",用来掩盖问题而非根本解决。测试人员可能仅关注重试后成功的结果,忽视初次失败的警示信息,进而形成对测试失败的"免疫",降低对代码质量或应用性能问题的敏感度。这种误用不仅破坏了测试的本质价值,还可能造成严重的技术负债,阻碍软件产品的持续改进和功能稳定。
反观合理利用自动重试机制,则能带来显著的帮助。测试失败本质上反映了产品行为在特定条件下的异常表现。对于无法轻易复现的间歇性失败,自动重试机制自动触发的额外执行正好提供了更多的反馈数据,帮助测试人员区分是可靠的功能缺陷还是偶发的环境或基础设施问题。通过分析重试次数中的失败和成功比例,团队能够高效分类问题优先级,重点解决频繁、持续的缺陷,而对偶发、影响较小的问题可以安排在后续迭代中逐步改进。在大规模企业级测试项目中,自动重试机制更是得到了广泛的认可。随着测试用例数量达到数千、数万,环境复杂度和资源共享程度提升,偶发性能问题、网络抖动甚至测试工具本身的偶发挂起都不可避免。
此刻,自动重试不仅节省了手动重跑测试的时间,也为测试报告提供了更丰富的上下文信息。如著名案例中的PrecisionLender团队利用自动重试捕捉了因为Selenium Grid资源波动引起的偶发失败,并通过报告中多次重试的结果快速定位问题性质,避免了大量无谓的排查工作。与此同时,合理使用自动重试机制需要配合完善的测试流程管理。团队应明确规定如何读取和分析重试结果,对于连续失败的测试用例进行及时排查和修复,避免自动重试变成掩盖问题的工具。自动重试不应成为忽视测试失败的借口,而应是风险评估和问题定位的利器。此外,加强测试代码的健壮性,优化等待策略,改进测试环境的稳定性,都是辅助减少间歇性失败,提高测试质量的关键手段。
行业内一些先进的测试框架和工具也提供了针对自动重试的细粒度配置及报告能力。如SpecFlow+ Runner允许设置重试次数并在报告中以颜色区分失败的持续性和间歇性,这种直观的表现形式有助于测试团队即时判断问题优先级。结合日志、截图等调试信息,自动重试机制能够成为测试工具链中不可或缺的组成部分。需要强调的是,自动重试并非万能方案。对于根本性缺陷、功能设计缺陷及开发代码中的严重错误,重试绝不会带来真正的"幸运",其失败会持续暴露。相反,将有限的时间和精力投入到排查这些一致性高的失败,对保障软件质量和用户体验的提升意义更大。
另一方面,对于确实由环境抖动或异步操作引起的偶发失败,恰当的自动重试可以提高测试的稳定性和可信度,让团队成员不必在每天早晨面对一大堆误报而焦头烂额。自动重试的有效实践还需结合团队文化和项目背景调整。如敏捷开发中强调快速反馈和持续集成,自动重试有助于快速筛出高优先级问题,支持快速修复和迭代。大规模企业项目侧重稳定和精确,重试机制则需要与监控告警、根因分析等体系联动,达成闭环管理。对小规模或初创项目,过度依赖重试可能增加复杂度,不如优化测试质量和环境稳定更有效。总的来说,自动重试是双刃剑,既能提升自动化测试的效率和深度,也可能引发懒惰和掩盖问题的负面影响。
测试团队应秉持严谨、开放的心态,认识到自动重试的本质 - - 它是辅助收集信息的工具,而非替代品。通过结合重试结果的深入分析、及时处理问题和持续优化测试体系,测试自动化才能真正发挥价值,助力软件产品安全快速地走向用户手中。自动重试机制不是万能钥匙,但合理使用将成为提升测试智能化水平的重要砝码。 。