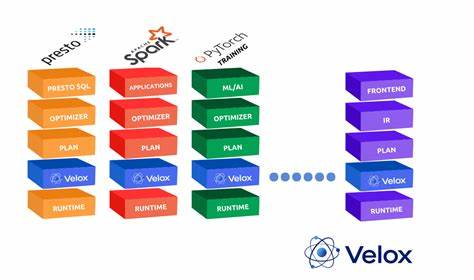
随着大数据技术和人工智能的快速发展,底层计算引擎的性能和扩展性成为衡量现代数据管理系统核心竞争力的重要因素。Velox作为一款由Meta(前Facebook)开发的开源C++执行引擎库,以其可组合、可扩展及高性能的特点,逐渐成为业界关注的焦点。作为底层数据处理组件,Velox为构建多样化的分析和计算系统提供了坚实基础,涵盖批处理、交互式查询、流处理以及AI/ML等多种应用场景。本文将带您全面了解Velox的设计理念、核心特性、架构组件及其在实际应用中的价值。首先,Velox并非一个完整的数据库或SQL引擎,它不提供SQL解析、数据框架或者查询优化器,而是聚焦于执行层面的高效计算逻辑。开发者通常将Velox嵌入到更高层的数据引擎中,利用其丰富的执行算子、高效的表达式求值及多种文件存储接口,实现快速且灵活的数据处理能力。
Velox的核心优势在于其模块化和可扩展性。它内置了一套通用的数据类型系统,支持标量类型、复杂类型和嵌套类型,如结构体、数组和映射等。基于Apache Arrow兼容的列式内存布局,Velox实现了多种数据矢量编码,包括平铺(Flat)、字典编码、常量编码以及序列编码,配合惰性物化和乱序写入支持,极大提升了数据访问效率和计算性能。在表达式求值方面,Velox采用全矢量化执行架构,能够高效处理基于矢量数据的算子和函数,支持包括标量函数、聚合函数及窗口函数等丰富的操作集。其函数库兼容Presto和Spark的语义规范,方便开发者快速移植业务逻辑。算子层则涵盖广泛的关系代数操作,如扫描、过滤、投影、分组、排序、连接(包括哈希连接、合并连接、嵌套循环连接)以及分布式执行中的shuffle和交换等。
此类算子的高效实现,保障了复杂查询执行的性能瓶颈得以有效突破。Velox还提供了灵活的I/O接口,支持多种文件格式(如ORC、DWRF、Parquet以及Nimble等)和多样的存储系统适配器,包括主流公有云存储服务(AWS S3、Google Cloud Storage、Azure Blob Storage)及本地文件系统。网络序列化层支持多协议接入,确保数据在分布式环境中的高效传输。资源管理方面,Velox集成了多种内存和计算资源调度策略,包括内存池、缓冲区管理、多线程执行模型与任务驱动架构,能灵活应对大规模计算场景中的资源约束、缓存溢写及任务协同,提升整体系统稳定性和吞吐能力。在扩展性方面,Velox允许用户自定义类型、向量化函数、聚合及窗口操作、算子以及文件格式和存储适配器,进而满足不同业务和系统的专属需求,保障技术迭代和生态环境的持续繁荣。作为一个开源项目,Velox不仅拥有Meta的强力支撑,还得到了IBM、Intel、Microsoft、ByteDance等多家行业巨头的积极参与,推动技术的不断完善和多场景落地。
对于开发者而言,Velox的文档丰富且社区活跃,支持通过GitHub、Slack等渠道参与讨论和贡献代码。它采用Apache 2.0开源许可协议,确保了广泛的集成和二次开发自由。在实际应用中,Velox帮助构建了高效、低延迟的分析系统。它通过对矢量化计算的极致优化,显著降低了CPU指令的执行周期,尤其适合现代CPU的多核并行和SIMD指令集。Velox还支持多平台编译,能够充分发挥x86及ARM架构的指令优势,满足多样化硬件环境需求。对于云时代下的大数据处理需求,Velox提供了可插拔的文件格式与存储接口,使得数据湖、数据仓库以及实时流式处理平台能够快速集成,避免了重复造轮子的成本。
其网络序列化支持不同主流协议,促进不同计算节点和引擎间的无缝协作,提升整体系统的扩展弹性和稳定性。从技术趋势看,随着数据分析技术对性能和灵活性的双重要求不断提高,Velox所代表的执行引擎库将成为新一代数据引擎架构的核心组件。它以高性能的内存布局和先进的执行策略为基础,促进了数据处理从单一平台向多引擎、多场景融合的演变。未来,Velox有望进一步扩展对AI/ML推理和训练的支持,推动数据管理系统向智能化、自动化方向发展。总结来说,Velox作为一款可组合、可扩展的高性能C++执行引擎库,已经在业界树立了标杆。它以精巧的设计、高效的执行和多样的接口配置,满足了从批量分析到实时计算乃至AI推理的各种应用需求。
对于追求性能极限和高度灵活性的现代数据平台开发者而言,深入掌握和应用Velox将大幅提升系统竞争力,并开拓创新空间。随着开源社区的壮大和技术的日趋成熟,Velox正在成为连接未来数据计算世界的重要枢纽,为构建更加智能、高效和协同的数据生态奠定坚实基础。 。