随着数字化时代的不断发展,PDF文件作为信息传递与存储的主流格式之一,广泛应用于合同、发票、研究报告等多个领域。然而,对于数据工程师和开发人员来说,从PDF中精准提取有价值的信息并非易事。尽管Python凭借其丰富的库生态成为数据处理和自动化领域的首选语言,但在PDF解析的过程中仍然会遭遇诸多挑战,本文将全方位剖析这些挑战的根源,并探讨相应的解决方案。 首先,解析PDF文件的最大难点源于其数据的非结构化特性。PDF设计初衷主要是为了保证文档的视觉呈现,而非方便数据提取。这意味着同一类型的信息在不同的PDF文档中可能呈现出截然不同的布局和格式。
尤其是那些包含文字、图片、表格混合排版的文档,若采用单一的提取规则,往往难以实现精准的内容分辨与匹配。 此外,一些PDF并不是通过电子方式生成,而是扫描的实体文件,这类文件的文字信息是嵌入在图像中的。仅凭常规的文本提取工具无法读取其中内容,必须借助OCR(光学字符识别)技术才能转换成可编辑文本。OCR技术本身会受限于图像分辨率、字体风格以及文档清晰度,错误率较高,尤其是面对复杂布局或不规则字体时,准确率进一步下降。这使得整体数据质量的保障变得异常困难。 PDF的页面布局多样化也带来了额外困扰。
常见的多栏排版、嵌套表格以及反复出现的页眉页脚元素,都容易干扰解析工具。多栏排版往往导致内容顺序混乱,简单的逐行读取会造成信息错位或丢失。嵌套表格结构复杂,许多表格提取工具难以识别,导致提取数据不完整甚至错误。重复出现的路径页眉和页脚则可能被错误地当作正文内容,影响数据清洗和后续分析工作。 在面对大型PDF文件时,性能问题亦不容忽视。多页文档和高分辨率扫描文件对内存和计算资源消耗巨大,一些标准Python库在处理时可能导致程序崩溃或运行缓慢。
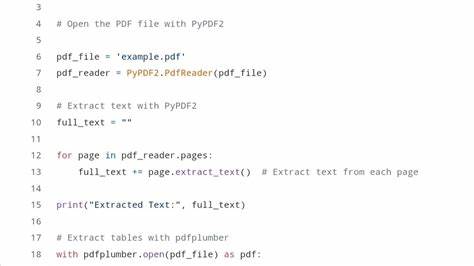
对于企业级应用而言,单线程处理速度已经难以满足需求,必须设计更加稳健和高效的数据处理流水线,甚至借助并行计算和分布式技术提升整体性能。 要想攻克上述难题,合理选择工具和技术方案尤为关键。Python生态中,PyPDF2可以较为有效地提取电子生成的PDF文本内容,而pdfplumber成为了结构化数据(尤其是表格)提取的佼佼者。对于扫描件,可以使用pytesseract结合pdf2image将图片转换为文本。虽然单独使用某款库可能会存在局限,通过组合多个工具的优势,能够满足更复杂的解析需求,提升整体数据提取的完整度与准确度。 近年来,随着人工智能技术的发展,大型语言模型(LLM)和视觉识别技术也被引入PDF解析领域。
借助带有视觉理解能力的模型,能够"理解"文档的排版结构,实现对多页、多格式、多布局信息的智能捕获和语义加工,显著降低手动设计解析规则的难度。部分平台还提供基于LLM的在线解析工具,通过自然语言查询方式快速定位和提取目标信息,极大提升办公自动化和数据分析的便捷性。 面对挑战,建立完善的数据质量检查机制同样必不可少。经过多轮OCR识别和数据抽取后,自动校验数据完整性与合理性,有助于及时发现异常与错误,保障后续数据处理和业务决策的可靠性。同时,灵活设计解析流程,支持动态调整规则和模型反馈,可以有效应对不同批次和格式变化的PDF文档。 在处理完数据提取阶段任务后,合理的后续处理也不可忽视。
解析出来的文本和表格需要规范格式、去重、统一单位等,方可为数据分析和业务智能提供高质量基础。此过程需要结合具体业务场景,设计针对性的数据清洗方案,确保信息展现的完整与准确。 总的来说,使用Python解析PDF文件虽然充满挑战,但依然可以通过科学的方法论和多元工具的协作实现高效且准确的数据提取。工程师需要在理解PDF底层结构和业务需求的基础上,灵活应用OCR、文本提取、多工具组合以及人工智能手段,构建从数据获取到校验再到整合的闭环流程。未来,随着算法优化和技术创新,PDF解析的自动化和智能化水平必将进一步提升,为数据驱动决策带来更多可能性。 。









