随着人工智能技术的迅猛发展,越来越多的大型语言模型(Large Language Models,LLMs)开始进入人们的视野。与此同时,传统上依赖云端的计算资源执行模型推理的方式,逐渐被能够在本地硬件上直接运行这些模型的新兴方法所取代。特别是对于拥有运行能力有限的中端笔记本用户来说,如何提升模型运行效率,并确保使用体验成为关键所在。本文将从硬件、软件到模型架构层面,详细解析如何在搭载NVIDIA RTX 3070 8GB显卡的笔记本上,借助Ollama框架顺畅高效地运行Qwen3 30B MoE模型,开启便携式本地AI推理新时代。 Qwen3 30B MoE模型作为大语言模型的代表之一,拥有大约30亿参数,然而其内置的Mixture-of-Experts(MoE)架构使得其每次运算仅激活模型中部分专家子网络,从而在保持高预测质量的同时,显著降低了实际计算开销。MoE模型通过专家路由机制智能分派计算任务,这种稀疏激活策略为消费级显卡如RTX 3070提供了运行空间,但同样对显存管理和调度带来了极大挑战。
使用RTX 3070这类主流游戏显卡进行本地推理,表面看似硬件规格有限,实则潜力巨大。RTX 3070配备8GB GDDR6高速显存和5120个CUDA核心,为AI模型推理提供了坚实基础。但由于显存容量不足以容纳所有参数及推理所需缓存,如何精细调配显存成为关键。本文借助Ollama 0.9.0版本,启用了CUDA后端及统一内存机制,成功通过限制和调节模型的上下文长度(num_ctx)及GPU层数(num_gpu),实现了在VRAM约7.5GB有效容量内维持稳定运行。 Ollama框架的Modelfile配置功能极为关键,其允许用户精确锁定每次推理所使用的上下文窗口大小及GPU承载的模型层数,使得复杂大模型的显卡显存利用率达到最优平衡。通过不断尝试不同数值组合,用户能够找到符合热控以及性能需求的最佳节点。
例如,将上下文长度设定为8192时,调整GPU层数以确保所有活跃专家且不触及统一内存阈值,避免性能骤降。 量化技术是保证Qwen3 30B在中端消费级显卡上高效运行的又一利器。采用Q4_K_M精度量化格式能大幅减小权重大小,兼顾准确性与显存需求。相比FP16格式,Q4_K_M在实际应用中表现出色,动态路由计算使得只有当前激活的专家权重被加载和计算,有效降低显存压力。用户通过重新量化权重并配合Ollama的Modelfile调节参数,实现了对30B参数规模模型的流畅调用。 硬件层面的稳定性是长时间运行的重要保障。
通过对笔记本GPU温度和功耗的监控发现,Gemma3和Qwen3 4B等密集计算模型典型 GPU温度稳定在71至73摄氏度,核心频率稳定;而Qwen3 30B MoE模型则因路由导致GPU计算负载波动,温度在65至68摄氏度之间波动,造成风扇偶尔频繁启动和停歇。借助自定义风扇曲线工具,如Tuxedo-Control,用户可平衡降温与静音需求,避免因温控波动带来的性能抖动。 此外,实际使用场景对模型选择也起着决定作用。短对话交互需求倾向于低延迟、小型密集模型,如Gemma3 4B Q8_0,其首令牌响应时间低至0.38秒,保证流畅聊天体验。长文本处理和批量文档摘要则更适合Qwen3 30B MoE架构,深度层数和专家模型优势显现,展现高度推理能力,但响应首令牌时间稍长。用户应根据自身的使用需求和负载特性选择合适模型以优化体验。
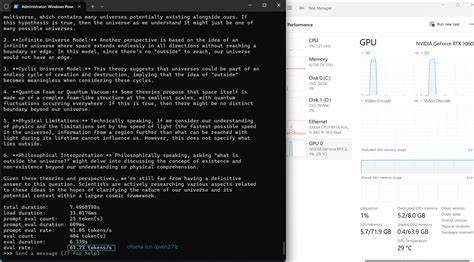
本地推理的另一个优势在于隐私性和持续可用性。全程离线运行消除了对外网连接的依赖,避免数据外泄风险。在网络条件差的环境中,也不受调度与流量限制影响,提升了生产力和稳定性。更重要的是,用户拥有模型权重的自主权,可随时调优和量化,满足特定领域的需求,实现真正定制化的人工智能服务。 在实践中,VRAM的细致管理至关重要,超过7.6GB的显存使用通常会导致CUDA驱动切换至统一内存模式(host-to-device),造成性能下降甚至崩溃。通过nvtop和Ollama日志细致追踪显存使用,用户可以实时观察显卡负载状态,迅速定位瓶颈并调整参数,避免泛音频启动和性能剧降。
能源消耗方面,即使是高负载运行,系统整体功率也维持在105至125瓦左右,符合主流笔记本电源设计标准,持续8小时高强度运行下人体接触面温度保持舒适,兼顾性能和人机体验。对于频繁使用AI模型进行代码生成或文本处理的研究者和开发者而言,避免了频繁外出充电或过度散热的困扰。 本地运行大模型对软件环境也有特定要求。文章采用Mageia Linux Cauldron发行版,结合专有NVIDIA 550.xx驱动及Ollama最新版本,多项优化开关确保CUDA后端和统一内存高效协同工作。此外,用户需确保llama.cpp编译时启用AVX2指令集优化,提升总体计算性能约30%。 当前方案仍存在一定局限性,如在Windows环境下复现稳定配置的难度及风扇控制表现有待验证,FP16量化模式由于显存限制而普遍低效,未来更高端显卡(如RTX 4080笔记本版)将为运行持续提供更宽裕空间。
另外,Ollama Modelfile格式专有属性限制社区生态开放,手动映射参数至其他推理框架依然耗时费力,这也提示并期盼行业推动统一的配置标准。 展望未来,解锁笔记本BIOS以提升TGP功率限制,将带来更佳的MoE模型运行表现;结合最新Sliced Attention技术及显存分页技术的新一代大模型测试也将呈现更多可能。业界期待在更轻便硬件上实现近似GPT-3.5级别的离线推理,而便携设备如Steam Deck的尝试引发极大兴趣。 总体来看,借助精准的显存管理策略、合理量化权衡及灵活参数调节,Qwen3 30B MoE模型已成功跻身中端RTX 3070笔记本的运行行列,为用户带来强大且私密的AI推理能力。相比昂贵云端推理,本地运行不仅降低了使用成本,还带来了更高的灵活性和稳定性。对于AI爱好者、开发者及研究人员来说,掌握上述优化技巧和调试思路,无疑将极大提升日常AI工作效率,推动本地智能应用实现更多创新和可能。
。