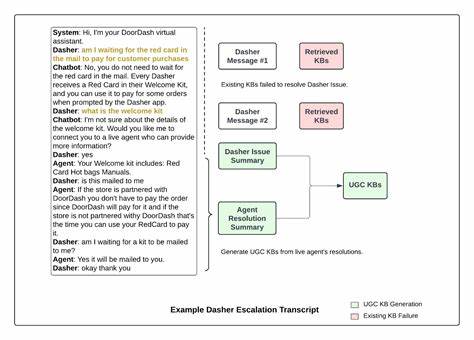
随着人工智能和大数据技术的迅猛发展,数据类型的多样化已经成为数据库领域的一大挑战。传统的数据库管理系统主要处理结构化数据,而在现实应用中,图片、音频与文本等非结构化数据占据了重要比例,如何高效地存储、查询和分析这些多模态数据成为迫切需求。ThalamusDB作为一款创新的数据库系统,通过内嵌大语言模型(LLM)实现了对多模态数据的语义级SQL查询处理,为行业带来了全新的解决方案。 ThalamusDB的最大亮点在于其强大的语义查询能力。用户能够通过熟悉的SQL语句结合自然语言指令,直接操作图片、音频和文本数据。例如,在处理图片数据时,只需要在SQL中使用特殊的语义函数如NLFILTER和NLJOIN,系统即可自动识别图片内容,实现基于视觉语义的筛选和关联。
这种能力彻底打破了传统数据库仅能基于元数据进行查询的局限,让用户能够更自然、更高效地探索多模态数据。 具体来说,NLFILTER函数允许用户利用自然语言描述对图片进行筛选,如查找"海滩的照片"。NLJOIN则基于图片语义特征,将不同表中的图片进行匹配,比如识别出同一个人出现在多张照片中。这种以语义为中心的处理方式,极大地简化了多模态数据的查询逻辑,提升了用户体验和查询的准确性。 不仅如此,ThalamusDB还支持对音频数据的处理,允许用户对WAV、MP3格式的音频文件执行语义分析。通过集成针对音频的LLM,系统能够识别音频内容、情感、关键词等,使得用户可以在SQL环境下直接做音频的内容搜索和对比,推动了语音数据的智能探索。
在文本数据的处理方面,ThalamusDB同样体现出不凡的实力。它不仅支持传统的文本存储与搜索,还允许用户利用自然语言指令对文本内容进行深层次的语义分析,实现语义过滤、主题挖掘和信息抽取等操作。这种深度集成的能力简化了多模态数据融合分析的流程,提升了整体的数据处理效率。 值得关注的是,ThalamusDB采取了创新的成本控制机制,以应对多模态语义查询在计算资源上的高需求。用户可以为每个查询设定成本上限,系统则会在既定的预算内,采用近似处理技术生成最优结果。同时,用户还能约束查询误差范围,系统根据约束调整计算策略,保证结果的可靠性和及时反馈。
这种灵活的成本与精度平衡策略,为实际应用中的资源利用提供了有力保障。 在查询过程中,ThalamusDB还会实时展示部分结果,帮助用户快速把握查询动态,及时作出调整决策。这种渐进式结果呈现极大地提升了查询的交互体验,避免了传统大规模语义计算导致的长时间等待和资源浪费。 与其他同类引擎相比,ThalamusDB独特地聚焦于近似查询处理和多模态语义操作。诸如LOTUS、Palimpzest、FlockMTL和CAESURA等引擎虽然在文本和图像处理上具备一定能力,但ThalamusDB在支持音频处理和成本约束机制方面展现了显著优势。此外,它提供的完整SQL接口结合自然语言功能,使得技术门槛更低,便于各类用户快速上手和集成到现有系统中。
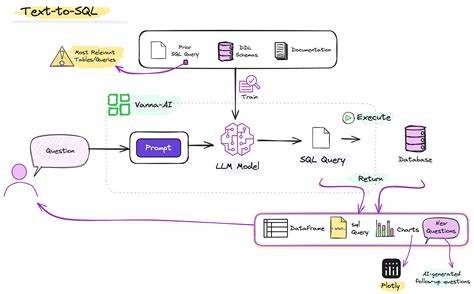
从技术实现角度看,ThalamusDB的核心依赖于最先进的大语言模型,通过自动识别数据文件类型,智能选择合适的模型进行语义解析和特征提取。这种高度自动化的处理方式避免了繁琐的数据预处理工作,也确保了对不同格式和内容的多模态数据有统一而有效的支持。 为了推广和支持用户,ThalamusDB提供了丰富的文档和研究论文资源,详尽介绍了系统架构、使用方法和理论基础。用户可以通过PIP轻松安装,并通过交互式控制台执行语义SQL查询,这为广大开发者和数据科学家搭建了一个便利的实验和生产环境。 未来,随着数据多样性和智能化需求不断增长,ThalamusDB所开创的语义多模态SQL查询模式必将引领数据库技术的新潮流。无论是企业级应用还是科研项目,基于ThalamusDB的解决方案能够有效整合图像、音频和文本资源,实现数据价值的最大化。
总之,ThalamusDB通过将传统结构化查询与现代大语言模型技术深度结合,解决了多模态数据处理的核心难题。其智能语义过滤和连接、灵活的近似计算成本控制以及渐进式查询反馈,为用户带来了前所未有的多模态数据管理体验。对于期望在复杂数据环境中实现快速、准确且经济高效数据分析的组织而言,ThalamusDB无疑是一款值得关注和投入的前沿技术平台。 。