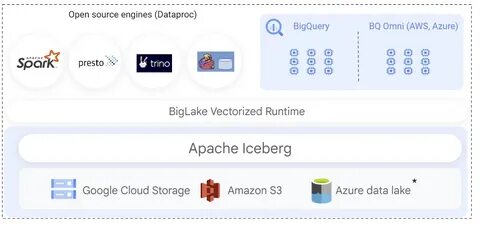
在快速发展的区块链领域,数据处理和分析的效率至关重要。随着交易量的增加,对数据处理的需求也持续上升。为了满足这样的需求,采用现代开源数据栈显得尤为重要。其中,冰山(Iceberg)、Apache Spark和Trino的结合,正为区块链带来了全新的数据处理与分析能力。 冰山(Iceberg)是一种开源的表格式数据存储解决方案,能够在大规模数据集上实现高效的数据版本控制和快照。它不仅支持多种数据源,包括Hadoop和云存储,还可以与常见的数据处理工具集成,实现数据的高效管理。
而且,冰山尤其适合用在需要实时数据分析的场景,比如区块链。 首先,区块链的数据结构具有非常独特的特性。交易记录是不断更新的,数据需要保持准确且实时。在这样的背景下,冰山可以提供极好的版本控制功能,使得用户能够追踪数据的变化历史。此外,冰山使用的是列式存储,这对区块链中常见的查询工作负载十分友好。 与冰山配合使用的,是强大的数据处理引擎Apache Spark。
Spark因其快速的内存计算和灵活的数据处理能力,成为了大数据分析的首选工具。它能够处理各种规模的数据,并且支持多种编程语言如Java、Scala、Python和R。在区块链环境中,使用Spark可以快速分析巨量的交易数据,进行实时计算,甚至是机器学习和数据挖掘。 通过Spark与冰山的结合,开发者可以轻松地在大规模区块链数据上运行复杂的分析任务,提取出有价值的洞见。无论是实时监测交易流动性,还是分析用户行为模式,Spark都能提供高效的解决方案。 另一方面,Trino(原Presto)是一款强大的分布式SQL查询引擎。
它能够查询多种数据源,包括Hadoop、云存储以及关系型数据库。Trino的优势在于它的查询速度极快,能够使用标准SQL语言对海量数据进行查询和分析。在区块链生态系统中,Trino可以帮助用户对不同的数据源进行集成查询,从而实现跨链的数据分析。 使用Trino,可以将区块链上的交易数据与其他系统的数据结合起来进行深入分析。例如,用户可以同时查询区块链的交易记录和与其相关的社交媒体数据,从而获得更全面的视角。这种能力在区块链项目的市场分析和用户研究中至关重要。
与此同时,这种现代数据栈的组合还为区块链的可扩展性提供了支持。随着链上数据量的不断增长,冰山、Spark和Trino共同构建的架构可以灵活扩展,使得处理能力可以随着需求的增长而提升。在数据量巨大的情况下,用户无需担心性能瓶颈,系统安全性和稳定性也得到了有力的保障。 要实施这个现代开源数据栈,首先需要基础环境的搭建。以下是实现这套解决方案的几个关键步骤: 1. **环境配置**:在云平台或本地服务器上安装和配置Hadoop,确保可以进行数据存储和分发。其次,部署Apache Spark,并配置其与冰山的集成。
2. **数据管理**:使用冰山表格式来管理区块链数据,确保数据的版本控制和快照功能正常运作。 3. **数据分析**:通过Spark编写与区块链相关的分析任务,进行数据的洞察和机器学习。 4. **查询整合**:使用Trino,配置与不同数据源的连接,利用SQL进行集成查询。 这一现代开源数据栈为区块链行业带来了更高的效率和灵活性。在数据驱动决策日益重要的今天,企业和开发者应考虑采用这类技术,以便更好地利用区块链的潜力。通过对这一工具栈的深入理解和应用,我们将能够更好地应对未来数据处理的挑战,推动区块链技术的持续发展。
总的来说,冰山、Spark和Trino的结合创建了一个强大的现代开源数据栈,为区块链领域提供了强大的数据处理和分析能力。随着区块链技术的深化应用,未来的机会与挑战将不断出现,而这种开源的技术组合有助于推动整个行业的进步。