近年来,随着人工智能特别是大规模语言模型的迅猛发展,模型规模和训练数据的需求与日俱增。传统的Transformer结构依赖于点积注意力机制,为模型捕获序列间的依赖关系提供了有效手段。然而,面对不断扩大的数据集和模型规模,点积注意力在计算性能和数据利用率方面逐渐显露出瓶颈。与此同时,现代模型越来越不再单纯处于计算受限状态,而是开始更多受到数据和token效率的制约,这为算法层面的创新提出了新的挑战和机遇。为了解决这些问题,近期一项创新性的研究引入了2-单纯复合注意力(2-Simplicial Attention)的概念,该方法在Triton这一高效内核环境中得到了实现和验证,展示了其优于传统注意力机制的多项优势。2-单纯复合注意力最本质的区别在于它将关注点从传统的二元关系扩展到了三元关系,通过三线性函数的形式,更加丰富地捕获了序列元素之间的复杂交互。
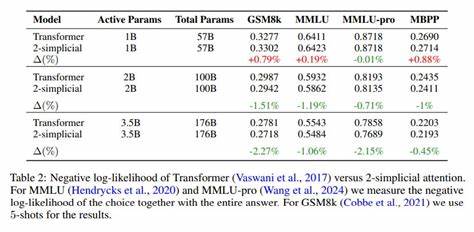
这种架构设计不仅使模型更具表达力,还有效增加了token的利用效率,即在相同的token预算下,模型能够获得更高的性能提升。在实际应用中,2-单纯复合注意力特别适用于数学、编程、逻辑推理等需要复杂结构理解和推断的任务。相关实验显示,采用该机制的模型在相同规模和token数量的条件下,明显优于采用传统点积注意力的模型。这表明2-单纯复合注意力在促进知识学习和加强推理能力方面具有显著优势,且其改进不仅限于简单精度提升,更体现在对训练规模和token数之间关系的底层刻画上,显著改变了相关的比例定律。这种优势的实现,离不开Triton这一专门为深度学习核函数优化的编程环境。Triton通过提供灵活且高效的CUDA内核开发框架,使得2-单纯复合注意力能够在不牺牲运行速度的前提下实现更复杂的计算模式,极大地提升了模型训练的计算效率和资源利用率。
在当前人工智能领域,训练数据呈现爆炸性增长,如何兼顾计算资源和数据有效利用成为核心问题。2-单纯复合注意力通过提升token效率,为解决这一难题提供了新的视角和方法论,尤其适合未来往更大规模、多任务以及更高智能水平发展的模型。2-单纯复合注意力的提出不仅是对Transformer架构的有力补充,更在理论和实践两方面推动了对注意力机制本质的深入理解。它引领了从传统二元关系向多维结构关系的转变,丰富了模型对复杂信息的表征能力。此外,这种机制的设计理念也激发了研究者对高阶结构信息的探索,促进了图神经网络、多模态学习等交叉领域的发展。尽管2-单纯复合注意力表现卓越,但其引入的计算复杂度相较传统方法有所增加,这就需要像Triton这样的高效内核技术予以支持。
未来,随着硬件计算能力的提升与软件优化技术的深化,这些挑战有望被逐步克服,从而实现更大规模和更复杂任务的高效处理。展望未来,2-单纯复合注意力有望成为大型语言模型和智能系统设计的新趋势。它不仅助力模型在有限训练预算下实现性能突破,还推动研究者重新思考模型的结构设计和效率平衡。随着更多应用场景的涌现,尤其是在需要深度推理、结构化理解及复杂策略制定的领域,该机制的独特优势将被进一步挖掘和发挥。总结来看,2-单纯复合注意力代表了现代深度学习架构的一次重要进化。通过对传统注意力机制的结构性扩展及在Triton环境下的高效实现,它有效提升了模型的token效率和推理能力。
在数据规模与计算资源共同增长的趋势下,这种新型注意力机制为推动智能模型的可持续发展和应用普及提供了坚实基础。未来,伴随更多理论研究和工程实践的结合,2-单纯复合注意力有望在推动自然语言处理、逻辑推理、编程自动化等诸多领域实现新的突破,助力人工智能迈向更加强大和高效的新阶段。