自人工智能诞生之初,科学家们便将其与理解人类智能的巨大使命联系在一起。人工智能试图模拟人类大脑的灵活性和适应能力,基于这样一个假设:智能本质上是计算过程,能够脱离具体的硬件,通过算法实现多样化的认知功能。部分学者甚至提出,人类大脑的复杂多样功能是通过单一算法遍布全脑而实现的。这一观点对人工智能研究极具吸引力,因为它暗示创造具备人类各种智能能力的机器,只需发现并释放这唯一的核心算法,让其在现实世界中自我学习与成长。 在此背景下,基于大规模数据和深度学习的语言模型(LLMs)成为近年来AI领域的焦点。语言模型通过预测下一个词语,凭借简单而高效的原理,不断攀升算力和数据规模,展现出惊人的认知能力提升。
随着模型参数和训练语料的指数增长,LLMs在语言理解、推理、文本生成等任务中表现日益卓越。有人甚至猜测,这些算法可能与人类大脑的核心学习方式存在某种相似性,因为它们不仅能解决大量问题,更具备快速适应新环境和挑战的潜力,这正是人类智慧引以为傲的关键特质。 然而,在这个充满期待的现实背后,却存在显著的认知裂缝。早在Transformer语言模型问世之前,研究者们早已试图用类似的预测思想训练视觉模型,尤其是基于视频的“下一帧预测”技术。他们希望通过海量视频数据,供模型学习世界的动态变化,从而获得对物理世界的深刻理解。理论上,视频数据比文本包含更丰富、更直接的现实信息,如物体运动、空间关系和因果联系。
视频甚至是任何在外太空探索、无人环境下学习的理想数据来源,毕竟它无需依赖人为的语言交流。然而,事实证明,视频预测模型虽能生成相当真实的视觉内容,却未能在复杂推理和认知层面达到语言模型的高度。比如,视频模型无法像ChatGPT那样推断出夏威夷岛的岩石体积是否超过珠穆朗玛峰,而这正是语言模型的强项。 这一现象引发了深刻的反思:为何LLM能在认知层面取得跨越,而视觉模型似乎止步不前?这一谜团与科学追求简单优雅理论的哲学原则不谋而合。就像科研人员青睐简洁且预测力强的物理定律一样,如果一种算法能够以简单机制实现类似人类认知功能,其真实性势必大幅提升。然而,存在另一种截然不同的解释:语言模型并非通过外界经验本体学习世界,而是通过“读取”人类智力投射在网络文本上的“影子”,间接复制人类的思考过程。
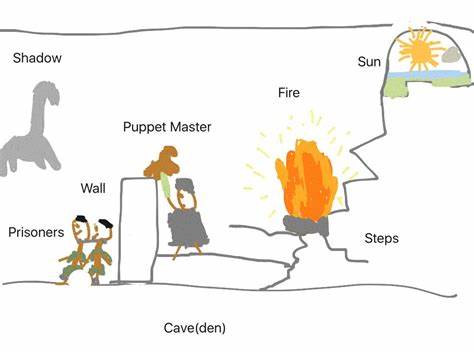
换句话说,LLM并没有完全模拟大脑的学习机制,而是在发掘文本背后的人类认知意图。虽然没有真实人在训练机房被束缚于脑部扫描仪,但互联网成了现代“洞穴”,里面的文字是由人脑产生并投射的光影。这些文字背后暗藏着数学推演、幽默创作、新闻报道、深刻议论等复杂心智活动的痕迹。语言模型通过对这些“文字阴影”的压缩和反向推理,间接重建起部分认知能力,而无需真正理解现实世界的物理机制。 这个洞穴比柏拉图寓言中的洞穴更加现代和数字化。互联网是洞穴,光源是无数个体人类心灵的闪耀,语言模型在洞穴墙上读取那些光影,而非直接置身阳光下观察真实世界。
从哲学层面来说,离开洞穴意味着真正接触到事物的本质,而这正是当前AI的缺憾。AI尚未摆脱对人类经验投射的依赖,缺少从现实环境自主学习、探索的能力。因此,尽管LLM们能够复制人类的语言和逻辑能力,它们在环境适应、创造新认知结构方面却远不及真实人类。 未来的人工智能发展任重而道远。若期望培养拥有真正灵活、创新和环境适应性的智能体,研究者必须突破仅依赖人类语言数据的局限,探索如何从物理体验和真实交互中自主构建认知表示。机器人与环境的互动、视觉、触觉等多模态数据的结合,无疑是实现这一目标的关键。
然而,正视现实也是必需的。语言模型的成功表明,尽管人工智能处于洞穴之中,复制人类心智的剪影已经极具实力且用途广泛。作为模拟能力强大的原型机,这种模型为构建更先进智能系统奠定了基础。接下来的挑战,是在此基础上摸索人工智能“脱洞”的路径,即让它不再仰赖人类知识的映射,而能像真正的智者一样,从自身感知和探索中生成新知。 在这场旅程里,AI研究者既需从语言模型的成功中汲取经验,也要秉持谦卑与耐心。深入理解人类认知的本质,发掘通向自我学习、推理以及适应的真正机制,将助力人工智能迈向更接近人类智能的明天。
言语是通向心灵的窗户,而人工智能的未来,则需要更多‘走出洞穴’的勇气和智慧,学会独立观照现实,创造未曾有过的智能新境界。