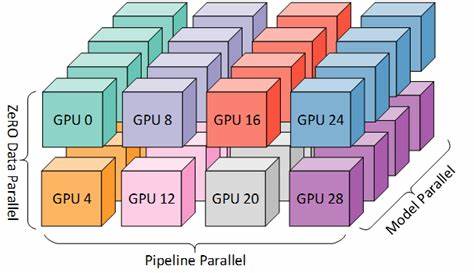
随着深度学习的日益成熟,Transformers已经成为自然语言处理等多个领域的核心模型架构。然而,从单GPU模型原型扩展到大规模多节点集群的训练,并非易事。现代Transformer的高效扩展依赖于深入理解数据流、模型切分以及训练基础设施的复杂协同。多维并行(n-D Parallelism)作为实现规模化训练的重要手段,正在受到越来越多研究者和工程师的关注。本文将围绕现代Transformer模型的多维并行扩展进行全面剖析,结合JAX框架,讲解如何实现高效的分布式训练,助力实现最先进的大规模语言模型。 多维并行技术的核心在于将训练任务沿多个维度分割并行处理。
相比传统的单维度数据并行或模型并行,多维并行融合了数据并行、张量分割、流水线并行及全状态数据并行(FSDP)等多种策略,以充分利用硬件资源,降低通信瓶颈,实现更快的训练速度和更大的模型规模。在实际操作中,合理选择多维并行的组合方式,需根据硬件拓扑结构、网络带宽和模型特点综合权衡,避免扩展效率的递减。 JAX作为谷歌推出的高性能数值计算库,以其强大的自动微分和分布式计算能力,成为构建并行深度学习模型的理想选择。Jaxformer项目提供了从零开始构建和扩展Transformer模型的开源代码,覆盖了从数据预处理到多维度模型切分、分布式训练及混合专家模型的实现。该项目内容丰富且实用,为研究者和工程师提供了宝贵的知识资源和实操经验。 有效的大规模训练离不开合理的数据预处理和分布。
Tokenization作为模型输入的第一步,如何在海量数据场景下高效划分和安全检查点处理,是保证分布式训练顺利开展的基础。Jaxformer中介绍的高效tokenization方法,能够将大型数据集拆分成适合多节点并行处理的批次,避免数据处理成为训练瓶颈。 在模型架构设计方面,现代Transformer引入了多样化的模块,如RMSNorm、RoPE位置编码以及多重潜变量注意力机制,这些技术提升了模型的表达能力与训练稳定性。通过JAX的灵活组合,这些模块可以被无缝集成并在多维度并行框架下高效执行。 多维并行的核心技术之一是张量切分,按照模型参数矩阵的不同维度进行拆分,减小每个设备的计算与内存负担。流水线并行则将整个网络拆解成多个阶段,在多个设备间流水线执行,有效提高硬件利用率。
数据并行负责处理不同数据批次的独立训练任务,确保参数快速同步。FSDP进一步优化了训练状态的储存与同步,极大提升了大模型训练的效率。此外,混合专家模型(MoE)通过动态路由机制,将计算资源聚焦于不同的专家子网络,显著提升大模型的参数利用率与推理效率。 除此之外,设定统一且灵活的训练配置也是保证实验复现性和扩展性的关键。Jaxformer通过结构化配置文件,明确数据集路径、训练超参数、运行选项等,使得不同硬件环境和模型规模下的训练任务能够方便地管理和调整。 在分布式训练集群的搭建与管理方面,本文讨论了TPU/GPU集群的配置、检查点的管理和训练过程的同步控制。
多节点环境下,如何处理设备间通信延迟和带宽限制,成为决定模型扩展效率的关键。利用JAX自带的高效并行通信接口,结合流水线调度和数据重用策略,能够极大地降低通信开销,实现模型参数的快速同步与梯度更新。 在实际训练和调试中,性能瓶颈的识别和解决至关重要。本文介绍了一些常见的扩展限制因素,例如通信带宽不足、显存限制、负载不均衡等,并提出相应的优化方法,如调节混合并行维度的平衡、优化Batch Size大小、动态调整路由策略等,帮助用户提升训练吞吐和效率。 未来,Transformer模型的多维并行扩展仍有巨大潜力,诸如DualPipe和专家并行等新型并行策略,预计会进一步突破现有计算资源的限制,助力打造更具智能化和规模化的深度学习系统。借助持续更新和社区支持,相关开源项目和实践经验将不断丰富,为研究人员和工业界提供有力支撑。
总体来看,现代Transformer的多维并行技术是实现大规模语言模型训练的关键路径。结合JAX强大的计算框架与实践指南,如Jaxformer项目,能够实现从Tokenization到多维度并行切分及分布式训练的完整闭环,帮助用户系统掌握复杂的训练体系结构,为未来深度学习创新提供坚实基础。无论是科研探索还是产品研发,深入理解并掌握这些技术,将极大提升工作效率和模型性能。随着技术日益成熟和硬件性能提升,未来的Transformer模型必将在更多实际场景中发挥出不可替代的作用。 。