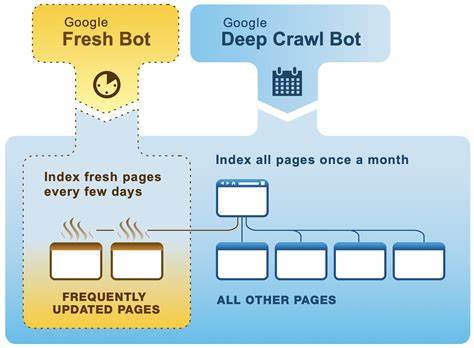
随着互联网信息的爆炸式增长,搜索引擎爬虫的作用愈发重要。爬虫不仅是搜索引擎获取网页内容的重要工具,更直接影响着网站的收录和排名表现。因此,“机器人能爬多深”成为网站运营者、SEO专家及内容创作者广泛关注的话题。理解爬虫的爬行深度及其影响因素,能够帮助我们更好地优化网站,提高搜索引擎可见度。搜索引擎爬虫的爬行深度,简单来说就是机器人从网站首页或入口页面开始,能够沿着链接路径深入多少层页面。爬虫并不会无限制地爬行网站,而是会受到多种因素的约束。
影响爬虫爬行深度的主要因素包括服务器响应速度、网页权重、链接结构、robots.txt文件设置、nofollow属性以及网站内容更新频率等。服务器性能越好,爬虫访问速度越快,能爬行更多页面。相反,若服务器响应缓慢或经常出现错误状态码,爬虫会减少爬行的深度与频率以节省资源和避免负载过高。网页权重是搜索引擎评估页面价值的重要指标,权重高的页面更容易获得爬虫的青睐,从而被优先抓取。网站整体权重较高,也能影响爬虫给予的爬行深度。良好的站内链接结构有助于爬虫顺畅爬行。
合理的目录层级、清晰的导航栏目、合理的内链布置,能够降低爬虫的爬行成本,延展爬行深度。相反,复杂难懂或链接错误的结构会限制爬虫爬行深度。robots.txt是网站管理员用来告诉爬虫哪些页面允许抓取、哪些禁止抓取的文件。错误或过度限制的robots.txt文件会阻断爬虫访问,直接影响爬虫的爬行范围和深度。同时,网页中的nofollow标签告诉爬虫不跟随某些链接,这也会限制爬虫的爬行深度及路径,减少无效页面的抓取。内容更新频率与质量也会影响爬虫的爬行深度。
高质量且更新频繁的内容更有吸引力,爬虫会加大爬取力度,深入挖掘网站结构的更多层级,从而扩大爬行深度。反之,死链、重复内容或低质量页面会减少爬虫的爬行兴趣,导致爬行深度受限。另一个重要的影响因素是爬虫本身的资源限制和算法策略。爬虫需要在短时间内高效抓取大量网站,资源有限时优先抓取高价值和热门页面,限制对低权重页面的深入爬行。大型搜索引擎如Google、Bing等使用复杂的算法决定爬行广度与深度,有时甚至基于网页的重要性和用户需求调整爬行行为。此外,技术层面上的网站架构也可能限制爬虫爬行深度。
动态网页生成、JavaScript渲染内容、AJAX加载异步内容等,可能让爬虫很难捕获完整页面信息。随着技术发展,越来越多爬虫具备了处理动态内容的能力,但仍面临一定挑战,从而影响其爬行深度。同时,网站安全设置、认证机制也会限制爬虫进入深层页面。实际操作中,了解爬虫爬行深度对SEO的实际意义尤为重要。深度抓取意味着网站页面被更全面收录,提升关键词覆盖率和流量。爬行深度不足则会导致重要页面未被索引,影响搜索表现。
要提升爬虫爬行深度,优化方法包括改善服务器响应、合理设置robots.txt及nofollow、建设清晰的站内链接结构、提升内容质量与更新频率等。此外,定期检查死链和重复内容,保持网站结构简洁高效,从而降低爬虫爬行障碍。网络安全方面,应避免过度认证或屏蔽,确保合法爬虫能够顺畅访问优质页面。要察觉爬虫爬行深度的问题,可以借助网站日志分析工具来查看爬虫访问的页面层级和频率,结合Google Search Console等平台的数据,判断抓取覆盖度。必要时,调整爬虫访问策略,或在站点地图中体现重点页面,增加曝光率。需要注意的是,不同爬虫的爬行策略大不相同。
比如AhrefsBot依据访问日志显示,具有较深的爬行深度,但也受到自身资源限制和目标网站策略影响。了解不同爬虫习性,有针对性地进行优化,有助于站点更有效地被多种爬虫识别和收录。未来,随着人工智能与机器学习技术在搜索引擎的深度应用,爬虫的智能化程度将进一步提升。基于内容质量、用户行为预测,爬虫可能更加精准地动态调整爬行深度,优化抓取效率。网站管理员需不断适应和优化,以迎合搜索引擎进化的趋势,确保网站内容能被充分发现和有效索引。总的来说,搜索引擎爬虫的爬行深度受技术、算法、服务器性能及网站结构多重因素影响。
通过合理设置和持续改进,网站运营者能显著提升爬虫的爬行深度,令网站在激烈的搜索竞争中脱颖而出,获得更多有价值的流量和曝光。