在现代数据驱动的应用中,数据库性能直接影响整体系统的响应速度和用户体验。PostgreSQL作为一款功能强大且广泛应用的开源关系型数据库管理系统,为开发者提供了丰富的优化手段。在众多优化技术中,理解关联性统计(correlation)和索引仅扫描(index-only scan)的原理及应用,对于提升查询效率有着至关重要的作用。本文将深入剖析这两大技术概念,结合实际案例揭示如何通过合理设计索引结构和优化物理数据布局,实现数据库查询的爆发式性能提升。首先,探讨PostgreSQL的存储机制是理解性能表现的基础。PostgreSQL采用的是“堆表”(heap table)结构,即数据以无序的方式存储在以8KB为单位的页面(page)中。
每一行数据拥有称为ctid的唯一物理定位标识,指明该行在特定数据页中的位置。相比有序存储,堆表虽能灵活支持并发和访问,但访问特定数据时若页面不在内存缓存中,则需要进行磁盘I/O,显著增加查询响应时间。为了提高检索效率,PostgreSQL引入B-树索引这种经典的数据结构。在B-树索引中,键值以顺序排列,查询时能快速通过键找到对应的数据行物理地址(ctid)。这种索引结构通常使查找数据的成本呈对数级增长,远低于扫描整张表。然而,仅凭索引加速定位行的过程并不总是足够。
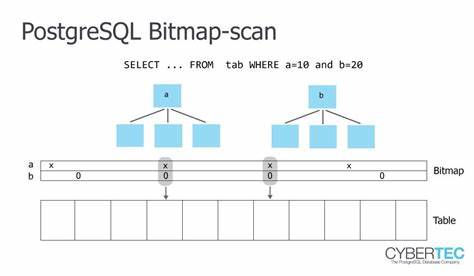
当索引条目顺序对应的物理行散落在堆表的不同页面上时,系统会反复进行随机磁盘访问,导致大量磁盘寻址和缓冲缓存竞争,极大拉升了查询的磁盘I/O负担。这里引出了关联性统计的核心意义。关联性表示行的物理存储顺序与索引键的逻辑顺序之间的匹配程度。理想状态下,关联性接近于1,表示数据物理排布与索引排序一致,因此访问时可顺序读取页面,减少随机I/O开销。相反,关联性接近0,则表明数据分布无序,索引扫描时访问的页面位置大幅跳跃,性能受到严重制约。正确理解这种统计数据有助于开发者判断索引的实际效果,避免盲目依赖索引而忽视其背后数据安排的物理影响。
当关联性不佳时,常规的索引扫描往往引发性能瓶颈,特别是在包含大量过滤条件且需要遍历数据获取的场景下,这种开销会被放大。为突破传统索引扫描中频繁访问堆表页面的限制,PostgreSQL提供了索引仅扫描机制。索引仅扫描的核心优势在于它完全从索引本身获取所有查询所需的列数据,无需回访堆表,彻底避免了随机磁盘读取。在利用此机制时,查询涉及的每个字段都必须包含在索引结构内,否则仍需访问堆表完成数据补充。此外,PostgreSQL利用可见性图(visibility map)机制判断数据行是否可见,从而避免访问堆表验证事务可见性,这也是索引仅扫描得以高效实现的重要前提。实际场景中,为了充分发挥索引仅扫描的威力,开发者往往需要设计覆盖索引,将查询中涉及的筛选条件字段与返回列全都纳入索引之中,实现“索引覆盖”。
例如,将字符串类型字段、时间戳字段以及主键id字段同时包括在复合B-树索引中,便能让查询执行器从索引页直接读取完整数据,免去读取堆表造成的频繁磁盘访问。本文开头案例揭示了一个高效优化实例:原先因物理数据顺序无规律,导致基于主键id的索引扫描性能极差,查询超时严重。分析关联性数据后,开发者发现id字段的关联性极低,这就是导致频繁随机访问堆页的根本原因。通过创建针对查询的复合覆盖索引,并执行真空操作刷新可见性图,系统成功采用索引仅扫描,大幅降低I/O负载,查询响应时间从数十秒降至不足一秒,性能提升令人惊叹。此外,此次优化期间也清理了冗余无用索引,帮助减少了缓冲池压力和写入开销,实现整体系统的健康恢复。尽管覆盖索引和索引仅扫描带来了巨大的读性能提升,但也伴随一些权衡,比如占用存储空间增大、写操作时索引维护成本上升等。
因此,在设计索引策略时需要综合考虑读写负载比例和存储资源。总结来看,PostgreSQL的查询性能优化不仅仅是简单的创建索引,更深层次的需要理解数据物理布局与逻辑访问方式的紧密联系,通过关联性指标洞察数据存储状态,并结合覆盖索引策略启用索引仅扫描,才能最大化减少随机磁盘访问,从根本上提升查询效率。数据库管理员和开发者应当定期分析表的关联性,合理设计索引结构,同时配合维护可见性图和执行VACUUM操作,确保索引仅扫描能持续稳定发挥作用。面对日益增长的数据规模和复杂查询场景,掌握并应用这些优化技巧将成为保持系统高效响应、降低延迟的关键方法。通过精细化的PostgreSQL调优策略,开发者能够在保证数据一致性的基础上,实现性能与资源利用的双重最优化,为业务增长和用户满意度提供坚实保障。









