圣经作为世界上最具影响力的古代宗教经典之一,其背后的作者身份一直是学术界长久以来关注和争论的焦点。尽管考古和历史学家通过各种方法不断探索圣经的生成过程,但因文本经过多次编辑与复写,加之历史环境复杂,使得对作者身份的判断尤为复杂。随着人工智能技术的快速发展,现代研究者开始尝试借助AI的强大数据处理及分析能力,揭开圣经隐藏的语言规律,进一步厘清不同部分文本的作者来源。近期,来自杜克大学及国际跨学科团队的一项突破性研究,结合人工智能、统计建模和语言学分析,成功识别出圣经中多个写作风格及其对应的可能作者群体,为古代文本研究开辟了全新路径。该研究主要关注希伯来圣经前九卷书,即所谓的“九书联合体”,通过对细微词汇使用及句式结构的比较,发现其中存在三种截然不同的书写传统或风格。团队利用AI驱动的统计模型,不仅实现了对已知文本的作者风格归类,还突破性地对争议章节进行了归属分析,披露了这些章节更可能的作者身份及其语言特征。
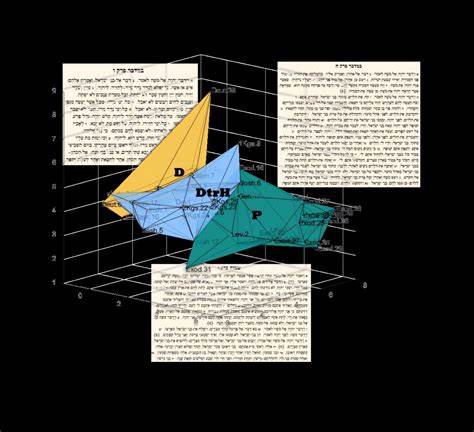
研究的核心在于利用人工智能分析文本中的高频词、不常见词汇及句子结构,寻找文本之间的相似与差异。相较于传统的文本分析方法,AI模型能够处理大量数据,捕捉人类难以察觉的细微语言差异,极大提升了研究的精度和效率。这种创新的方法有效应对了圣经文本篇幅短小且复杂多变的问题,克服了大多数统计学及传统机器学习方法对大数据量依赖的限制。杜克大学助理研究教授Shira Faigenbaum-Golovin率领的团队,最初借助数学和统计工具分析古代陶片上的铭文字体,从中总结出辨别手写体的技术。随后团队将此方法扩展应用到古圣经文本,结合考古学家、圣经学者、物理学家、计算机科学家等多学科专家的知识,形成跨界合作的研究模式。研究结果显示,申命记和被称为“申命历史”的历史书卷(约书亚记至列王纪)之间的语言风格高度相似,而与祭司书卷则截然不同。
这种现象与现有圣经学术界的共识基本吻合,但通过AI模型得到了数据上的量化证明和精细化解读。令人惊讶的是,AI能够通过分析如“无”、“哪一个”、“王”等常见词汇在不同文本中的使用频率及上下文关系,准确区分不同的作者群体。更为引人注目的是,在对《撒母耳记》中的方舟叙事段落进行研究时发现,尽管这些章节主题相近且常被视为同一叙事体的一部分,但《撒母耳记》第一卷与三大写作传统既无明显关联,而第二卷则显示出与申命历史书卷的亲缘关系。这一发现对理解文本的编纂历史提出了新的思考视角。在面对圣经文本数次编辑重写带来的语言变异和语境变化时,团队采取了保守且严谨的筛选标准,寻找那些相对保持原始语言风貌的片段,确保分析的有效性。通过模型的预测还可以对争议章节的作者身份进行量化判断,且模型不仅给出结果,还能解释背后的语言依据,这使得研究结论更具透明性和可信度。
研究负责人指出,这项方法不仅适用于圣经文本,还能应用于其他历史文献及其真伪鉴定中,为考古学、历史学和语言学交叉领域提供极具价值的新工具。未来团队计划将该方法推广至包括死海古卷在内的更多古代文献,期待借助人工智能的助力不断刷新我们对古代文本与文明的认识。这项研究的意义不仅在于技术的革新,更在于为古典文献研究注入了科学的严谨态度和全新的分析范式,让跨学科合作成为学术创新的驱动力。人工智能与人文学科的融合正在改变传统研究思路,推动人类更深刻地理解那些构筑文明基石的文化遗产。随着AI技术的不断完善,未来古代文本的神秘面纱将被逐步揭开,为人类提供更为丰富和准确的历史知识。综上所述,人工智能在揭示圣经隐秘语言结构及作者身份上的应用,不仅推动了圣经学的现代研究,更展现了科技与人文的辉煌结合,拓宽了学术研究的边界,成为历史文化研究的重要里程碑。
。