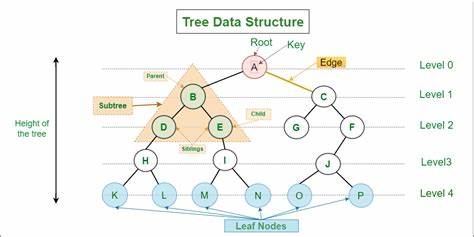
随着人工智能技术的迅猛发展,OpenAI再次打破了人们对智能语言模型的认知边界。最新发布的ChatGPT版本不仅在自然语言处理上实现了飞跃,更具备了视觉、听觉及语音交互的功能,使其能够看到、听到并且与用户进行语音对话,这一重大突破为人工智能赋予了前所未有的感知能力。过去,ChatGPT主要以文本为交互媒介,用户只能通过键盘输入文字进行交流。尽管这样的人机对话模式已经极大地拓展了智能助手的服务范围,但它仍无法满足许多需要多模式互动的实际应用需求。现在,随着ChatGPT能够"看"和"听",它具备了识别图片、声音和语音信息的能力,开启了丰富的感知体验和互动方式。视觉功能让ChatGPT能够理解并分析图片内容,这意味着用户只需上传照片,便可以询问其中的细节信息,或让模型帮助识别物体、场景甚至文字。
例如,在教育领域,学生可以通过上传实验结果图片,得到智能分析和解答,提升学习效率和兴趣;在商业场景中,企业能够借助图像识别帮助处理复杂的数据输入,优化运营流程。此外,听觉功能进一步丰富了ChatGPT的交互形式。它能够接收并理解用户的声音指令,识别环境声音,甚至进行声音情绪分析。这种能力使得用户无需键盘输入,通过语音与ChatGPT自然交流,大大提升了交互的便捷性和流畅度。对于视力障碍用户而言,这种多模式的交互方式尤其具有革命性,可以提供更为人性化和易于使用的智能服务体验。语音交互功能则实现了ChatGPT能够主动"说话",不仅具备语音合成能力,还能根据上下文进行自然流畅的对话交流。
这不仅使得AI助理更加生动形象,也极大地拓展了应用场景,如智能家居控制、虚拟客户服务以及远程教育等领域。用户能够通过语音指令控制家电、进行生活咨询,感受更为亲切和智能的服务体验。更值得关注的是,这些视觉、听觉及语音能力的整合,使得ChatGPT成为一个真正的多感官智能助手。它能够综合分析来自不同感官的信息,从而提供更加精准、丰富的回答和建议。例如,用户上传一张旅游照片,语音询问最佳旅游路线和当地文化介绍,ChatGPT便能通过图像识别结合语音交流,带来沉浸式的互动体验。与此同时,OpenAI在提升ChatGPT感知能力的同时,也强调了数据隐私和安全保护。
用户上传的图片或语音数据将严格遵守隐私协议,确保个人信息不被滥用。此外,模型的训练与更新过程透明且不断优化,以避免误识别和错误信息的传播,保障用户体验的可靠性和安全性。新一代ChatGPT的多模态交互能力还为各行业带来了深远影响。在医疗领域,医生可以利用视觉识别功能进行医学影像分析,辅助诊断;在零售行业,顾客通过语音和图像进行产品咨询,提升购物体验;在文化创意领域,艺术家能够用语言和图像共同创作,实现人机协作的新篇章。这种智能感官的融合,有望推动多个领域的数字化转型和智能升级。作为AI技术的领导者,OpenAI持续推动人工智能的边界,力图实现人机互动的自然化和智能化。
ChatGPT的新能力不仅为用户带来了全新的使用感受,也激发了开发者和企业的创新潜能,催生更多基于视觉和语音交互的智能应用。通过不断优化算法和模型架构,OpenAI致力于打造一个更加智慧、个性化且安全可靠的智能生态系统。总的来说,ChatGPT"看得见、听得见、能说话"的革命性进展,标志着人工智能从单一文本理解迈向真正多感官智能的历史性转折。未来的智能助手将不仅是信息的传递者,更是用户生活中的贴心伙伴,陪伴在日常工作、学习和娱乐的各个方面,推动社会进步与科技创新不断加速。随着选用和依赖这类智能工具的人群日益增多,我们也期待OpenAI能够持续深化技术研发,完善用户体验,引领人工智能迈向更加光明的未来。 。