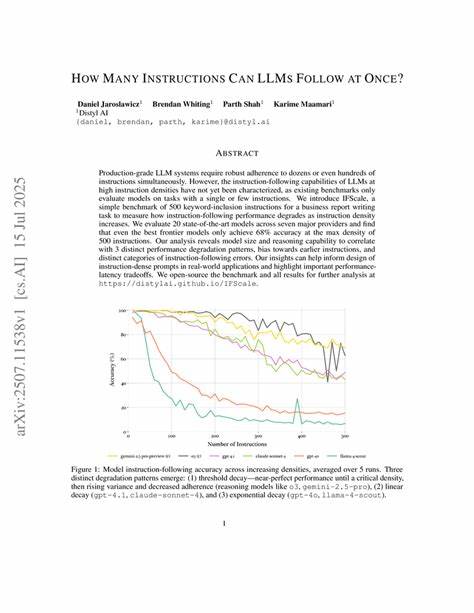
随着人工智能技术的飞速发展,特别是大型语言模型(LLM)如GPT系列的广泛应用,人们越来越关注这些模型在实际应用中能够同时处理多少条指令。这不仅关系到其多任务处理能力,也直接影响了AI系统的智能水平和适用范围。探索大型语言模型一次能执行多少条指令,对于理解其性能边界和开发更高效的应用系统具有重要意义。 大型语言模型的核心优势在于其强大的自然语言理解和生成能力。模型通过海量数据学习,建立了丰富的语言知识库,因此可以执行多种复杂任务。然而,当涉及同时处理多条指令时,LLM的表现会受到一系列因素的制约。
首先,模型的输入限制是关键因素之一。当前主流的LLM通常基于固定长度的上下文窗口,例如GPT-3的最大上下文长度为4096个标记(token),而最新版本如GPT-4则有所提升。这意味着模型在一次处理过程中只能接收一定长度的信息,当输入的指令过多或过长时,必须进行截断,导致部分指令信息无法被模型感知,进而影响最终输出的准确性和完整性。 其次,指令间的关联与复杂度也影响模型执行多任务的能力。若多条指令相互独立,模型可以将它们视为多个小任务同时处理,但若这些指令存在逻辑依赖或条件关系,模型则需要在生成过程中保持上下文连贯和逻辑一致,这就极大增加了理解和推理难度。同时,越复杂的指令序列对模型的计算资源要求越高,可能导致生成速度减缓或消耗更多的算力。
此外,当前模型的训练机制和优化目标决定了其对多任务处理的敏感度。LLM通常通过大量单一任务数据训练,虽然具备一定的泛化能力,但对于同时执行多条不同类型指令的能力尚未达到最优。例如,模型在同时需要翻译、写作和问答时,可能会出现输出内容混淆或优先级判断错误,影响用户体验。 为提升大型语言模型的多任务执行能力,研究人员提出了多种策略。一种方法是在训练过程中引入多任务学习,令模型在面对多种任务时不仅能切换自如,还能在任务间共享知识,提高整体表现。另一种方法是设计更智能的指令分解技术,将复杂指令拆解成更易处理的子任务,逐步完成,既缓解了输入长度限制,也增强了指令执行的准确度。
在应用层面,开发者往往通过合理规划交互方式,避免一次性提交过多指令,转而采用分步交互,这样不仅能保障模型响应的清晰度,也有助于用户更好地控制和调整任务进程。部分先进的AI系统还引入了上下文管理模块,动态调整输入输出信息,优化多任务并发处理效果。 关于模型未来的发展趋势,多模态能力与大规模预训练模型的结合将带来更强的多指令处理能力。通过整合视觉、语音等多种信息源,模型可以更加全面地理解复杂场景中的多重任务需求,提高同时执行多条指令的效率和准确性。此外,随着硬件性能的提升和模型架构的优化,模型的最大上下文长度将持续增长,为多任务处理奠定坚实基础。 然而,任何技术都有其极限。
目前大型语言模型虽然已经展现出惊人的语言理解与生成能力,但完全无懈可击地同时处理大量复杂指令仍面临挑战。模型在面对过多任务时可能出现信息混淆、优先级失调或生成歧义等问题,限制了其实用性和可靠性。因此,理解并合理利用模型的多任务处理边界,是打造高效智能系统的关键。 总结来看,大型语言模型一次能执行多少条指令并没有固定的数值,这取决于指令的长度、复杂度、关联性以及模型的上下文窗口大小和训练机制。虽然当前技术已经允许模型在一定范围内处理多条指令,但为了确保输出质量和响应速度,合理控制指令数量和设计有效的交互流程仍然十分重要。未来,随着算法和硬件的进步,LLM的多任务处理能力将不断增强,为人类带来更加智能和灵活的交互体验。
。