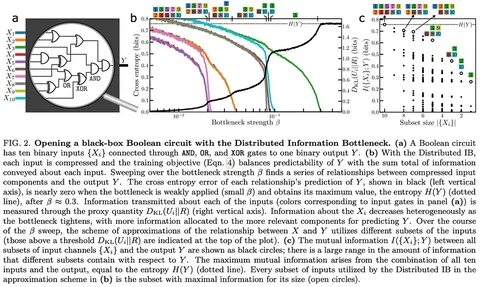
在当今数据驱动的世界中,信息的处理与提取能力变得越来越重要。随着机器学习和人工智能技术的快速发展,我们面临着如何高效地从海量数据中提取有价值的信息的挑战。针对这一问题,分布式信息瓶颈(Distributed Information Bottleneck,简称DIB)作为一种新兴的技术,正在逐渐引起研究人员和开发者的关注。这种方法通过分配和压缩输入数据的特征,旨在以最小的信息损失实现最佳的预测精度。 分布式信息瓶颈的基本理念在于对数据的各个特征进行独立的处理与编码。这种处理方式将每个特征视为独立的信息流,从而有助于在数据结构复杂的情况下,识别出最具信息量的特征,例如在医疗数据中,能够有效区分病人的年龄和病史,而在环境监测中,则可以分析湿度与温度的影响。
这种分布式方法的有效性,不仅体现在其对数据信息的提取能力上,更在于能够提供关于数据特征信息量的深入见解。 在传统的机器学习框架中,训练过程的结果往往是一个模型的性能极限,研究者们关注的是指标的提升与模型的保存。然而,分布式信息瓶颈的目标则是训练出一种能够持续反馈数据中信息分布的信号。通过有效的训练过程,不仅保存了模型,还记录了训练历史和与信息分配相关的所有重要数据。这种方法为了增强模型的可解释性,提供了关于信息如何在数据中流动的可视化结果,对于研究人员进行数据分析和模型优化都具有重要意义。 该技术的实现主要依赖于一个变分推断器,研究者们提出了一种称为DistributedIBNet的TensorFlow Keras模型,这使得使用这种方法变得更加简便。
用户只需通过标准的模型编译与训练接口(如model.compile和model.fit),就可以方便地观察与分析数据中的信息流动。此外,DIB引入了Kullback-Leibler散度惩罚项,以便在训练过程中逐步调整信息瓶颈的强度。这种策略对于在各阶段优化性能,确保信息分配的合理性至关重要。 具体而言,分布式信息瓶颈算法的训练过程包含多个步骤。首先,研究者需要初始化一个DIB模型,然后定义优化器和损失函数,接着设置一个用于信息瓶颈强度调整的回调函数。通过这样的结构,研究者可以迅速进行模型的训练,并在一定的预训练和调整周期内获得有价值的学习反馈。
这些反馈不仅限于模型的准确性,更包括特征的压缩矩阵和信息分配的动态演变,这些都展现了模型对于不同特征的敏感性与适应性。 分布式信息瓶颈的一个显著优点在于它的灵活性。在数据不是简单的表格形式时,比如时间序列数据或图像,研究者可以在输入特征之前,使用子网络来处理这些复杂数据。通过这种方式,能有效进行数据特征的提取和重组,更好地适应DIB的框架。这种灵活性使得DIB在多种应用场景下都能高效发挥作用,无论是在处理气象数据,还是在复杂材料的粒子信息汇聚方面,都展现了其独特的优势。 当前,分布式信息瓶颈正不断向更广泛的领域扩展。
研究人员们将其成功应用于各种实际问题,包括社交网络分析、金融预测、健康监测等,凡是涉及复杂特征提取与信息聚合的领域,都能找到DIB的身影。此外,这种方法的可解释性也极大地推动了其在学术界和工业界的应用,帮助研究人员和开发者理解模型的决策过程,从而提升模型的可靠性和接受度。 未来,随着科技的进一步发展和数据量的不断增加,分布式信息瓶颈的相关技术势必会不断完善和演化。研究人员也在积极探索与深度学习、无监督学习等技术的结合,试图形成更加强大和灵活的信息处理机制。通过将DIB与其他前沿技术相结合,可能会催生出更多具有创新性和高效性的数据处理解决方案。 总之,分布式信息瓶颈不仅是解决复杂数据问题的一种技术手段,更是推动数据科学研究与实践深入发展的有力工具。
随着其研究的深入与应用的拓展,未来的机器学习和人工智能领域,必将因 DIB 的出现而迎来新的发展机遇。研究者们将继续探索这条充满潜力的技术之路,让我们拭目以待。