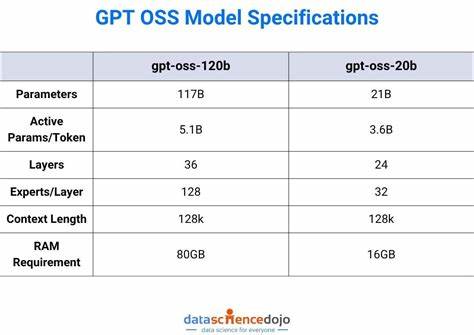
随着人工智能技术的迅猛发展,OpenAI作为全球领先的人工智能研究机构,其大型语言模型的训练数据一直备受关注。近日,OpenAI发布了其开源权重模型GPT-OSS,这一举措虽然提高了人工智能研发的透明度,却也意外暴露了训练数据的一些核心秘密,令业界和公众震惊。通过深入分析GPT-OSS模型的参数和词表内容,研究人员发现了许多训练数据中鲜为人知的细节,包括来自成人网站的短语、低频但高权重的"故障"标记,以及疑似源自GitHub的内容,揭示了OpenAI在训练数据选择和处理上的复杂性与潜在风险。 OpenAI官方对其训练数据来源始终保持高度保密,官方仅透露其使用了"以STEM(科学、技术、工程和数学)、编程及通识知识为重点的数万亿级文本语料库"。然而,GPT-OSS模型公开的权重为外界提供了前所未有的窥探窗口。通过对模型词嵌入(embedding)矩阵进行统计分析,特别是低L2范数和高L2范数的词表分布,研究者们揭示了训练语料中包含大量非标准词汇、方言表达和敏感词汇的事实。
所谓"故障"标记是指在模型词库中出现的特殊或异常令牌,这些令牌的训练数据出现频率极低,甚至可能未在训练中出现,但其嵌入向量属性异常,引发模型对这些词处理时出现奇异响应。通过分析这些"故障词",研究人员发现它们不仅涉及多种语言和地区方言,还意外包含了大量成人内容相关的短语,部分词汇在多种OpenAI模型(包括最新GPT-5)中均被识别,显示其至少曾在训练数据中出现过一次。这种现象被称为"成员推断",即通过模型表现推断某文本是否曾作为训练语料出现。 令人瞩目的是,这些已露出的成人网站词汇和涉及赌博、网络彩票的词汇在词表中的L2范数较高,意味着它们在模型训练中的权重较重,并非简单的噪声数据。这种高权重可能源于训练阶段对特定场景如代码推理、逻辑分析的强化学习更新,或者是因其在训练语料中频繁出现。此现象不仅证明了OpenAI训练数据涵盖了网络中各种类型的文本内容,同时也暴露了训练内容筛选机制的不足。
针对这些"故障标记",研究人员还发现它们在训练语料的语义覆盖上广泛散布,从阿布哈兹语到泰语、从中文到加尔各答方言,甚至包含政治极端主义及军事爱国主义网站的名称,令人颇感意外。包括"铁血网"等有政治倾向的网站出现在模型词库中,显示出训练爬取时对内容的选择标准未能有效排除这一类对地缘政治敏感的话题。此外,诸多异常词在网络存量中的活跃度与模型对其识别的正确率呈正相关,进一步暗示部分内容可能来源于公共代码托管平台,如GitHub。 通过对比GPT-OSS与同系列的GPT-5模型,以及其他开源和商用模型如Claude 4等,分析表明部分模型能准确翻译或解释这些敏感词,展现其在训练中真正"见过"这些字符串,而非随机推断。虽然OpenAI的模型在回应敏感内容时往往采取回避或轻描淡写的策略,但并未全面拒绝回答,反映出训练数据多样性和复杂性所带来的治理挑战。 开放权重模型的发布固然推动了人工智能领域的透明度,但也引发了数据隐私和安全方面的担忧。
训练数据内容的泄露可能成为恶意攻击者采取"成员推断"攻击的突破口,进而触发隐私泄漏、内容滥用等风险。尤其是那些出现过频率极低但嵌入权重异常的"故障"标记,更可能被利用制造模型异常行为,例如通过触发令牌循环导致拒绝服务攻击,增加云计算资源消耗,带来潜在的经济损失。 权威专家提出,为避免此类问题,未来的语言模型开发应更严格地控制词表设计,排除低频且敏感的异常令牌,并在训练之前对语料数据进行更全面的过滤和预处理。此外,加强对训练数据来源的监管,尤其是避免直接采纳未经筛选的互联网页面和开源代码库内容,确保内容合规和多样性平衡,成为打造更安全、更可信的AI模型的关键。 总的来看,GPT-OSS开源模型不仅为研究者提供了深度理解语言模型训练过程的宝贵资源,也暴露了训练数据采集、处理环节面临的诸多挑战和隐患。伴随人工智能技术逐步走向大众生活,如何在保证模型性能和多样性的同时,妥善维护数据隐私和内容安全,将成为行业发展的重要课题。
鉴于此,希望各AI开发者和研究者能够关注训练数据的合规性问题,通过技术和政策手段齐力推动人工智能的健康发展,使之真正造福社会。 。