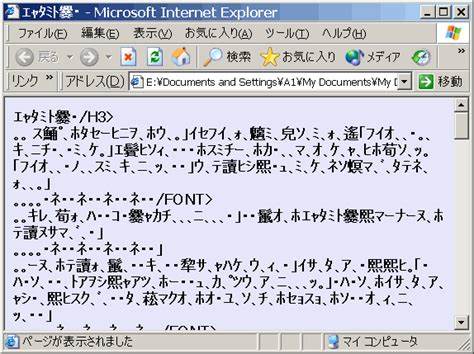
文字乱码,日文称为“mojibake”,意指“文字化け”,即文字显示出现异常、不正常或杂乱无章的字符,通常是由于文本被错误地解码为不匹配的字符编码而产生。随着数字信息交流愈发频繁,人们在浏览网页、使用应用程序、发送电子邮件时,都可能遇到文字乱码的困扰。理解文字乱码的成因及其背后的编码机制,对于提升数字交流的准确性和体验至关重要。 文字乱码本质上是编码与解码之间不匹配造成的结果。计算机文本信息并非直接存储字符,而是存储字符对应的二进制编码。不同字符编码(Encoding)将字符映射到不同的二进制代码。
常见的编码体系包括ASCII、UTF-8、UTF-16、Shift-JIS、GBK等。一旦输入文本的编码方式和显示时采用的解码方式不一致,原本正确的编码数据就会被错误解读,进而显示出无法识别的杂乱文字,也就是所谓的文字乱码。 在早期计算机仍未广泛采用统一编码的时代,不同地区和不同语言往往使用各自的定制编码方案。比如,日本常用Shift-JIS或EUC-JP,中文环境则有GB2312、Big5、GBK甚至GB18030,而西方国家普遍采用ISO 8859系列或Windows-1252编码。由于缺少全球统一标准,不同系统或软件之间传递的文本很可能因编码不匹配而产生乱码现象。 伴随着Unicode和UTF-8的普及,编码标准趋于统一和规范,但乱码问题依然存在,特别是当信息经过多重转换、或者某些环节未正确标注编码时,更容易导致错误解析。
加之某些应用程序或旧系统对新编码支持不足,兼容性问题仍带来不小困扰。 具体来说,文字乱码产生的原因主要包括编码标识缺失或错误,软件默认编码设置不同,以及编码转换错误等。举例来说,一份原本以UTF-8编码的文本,如果被软件当作Windows-1252解码,其中多字节的UTF-8字节会被单字节编码错译,令文字显示成“ä”这种毫无意义的字符组合。此类错误常见于网页服务器未发送正确的字符集信息,或者网页中缺少明确的编码声明,浏览器只好凭借默认设置尝试识别,最终导致乱码。 文字乱码不仅破坏阅读体验,还可能引发交流误解,甚至影响业务正常开展。各语言环境下的乱码表现各异。
在英文环境中,由于ASCII编码兼容性强,乱码多发生在特殊符号如引号、破折号或货币符号;而在中文、日文等东亚语言中,涉及多字节字符的乱码现象尤为明显,常导致整段文本完全不可辨识。 以中文为例,因存在多个编码体系,GB2312主要覆盖简体字,Big5主要涵盖繁体字,GBK和GB18030兼容更多汉字字符。若编码和解码不一致,如将GB2312文本错误解码为Big5,就会出现一串无意义字符。在日本,Shift-JIS和EUC-JP两大主流编码之间的混用,亦经常造成软件或网页中出现“文字化け”,干扰用户正常阅读。 针对乱码问题,现有的解决方案多集中于确保文本编码和解码的一致性。最根本的措施是统一采用Unicode编码,尤其是UTF-8。
UTF-8兼容ASCII,支持多语言,且易于识别,成为互联网和各种应用程序的事实标准。另一方面,文件、网页或通信协议应明确标注所使用的编码格式,减少盲目猜测和误判。 用户角度来看,遇到乱码时可以尝试手动更改软件或浏览器的编码设置,选择正确的字符集来重新加载文本。比如浏览器中可以切换到“简体中文(GB2312)”“繁体中文(Big5)”或“Unicode(UTF-8)”等编码查看效果。此外,许多现代编辑器和阅读器具备编码自动检测功能,可以智能识别并自动转换错误编码。 开发者在设计软件和网页时,应注意在数据交换和存储环节保留编码信息,比如使用HTTP头信息中的Content-Type字符编码声明,或在文本前添加字节顺序标记(BOM),让解析程序准确识别编码。
对于老旧系统或应用,可以通过安装支持多编码的补丁或字体包来提升兼容性,从源头减少乱码。 乱码背后折射出的是信息时代全球化与多样化的挑战。各国语言的独特字符和符号要求计算机系统具备强大的国际化支持。文字编码的历史演变充分体现了技术发展与文化需求之间的博弈。如今,虽然Unicode的广泛采用使乱码问题大幅减少,但在跨语言、跨平台、跨软件的复杂环境中,仍需警惕并妥善应对编码错配引发的异常。 此外,由于部分地区或设备仍使用非标准或者旧版编码,某些特殊情况仍然会导致乱码,需要依赖特定工具和技术手段进行修复。
例如,东南亚的一些民族文字在计算机支持较晚,编码标准尚未统一,而缅甸曾出现过Zawgyi字体和Unicode编码并存的不兼容问题,导致同一文本在不同设备上出现完全不同的显示效果。 出于安全角度的考虑,编码错误还可能成为恶意攻击的入口,如跨站脚本(XSS)攻击中经常涉及字符编码的绕过。因此,网络与应用安全防护也需重视编码的正确处理和验证,防止因乱码而造成漏洞风险。 面向未来,随着5G、物联网、人工智能等新兴技术的兴起,数据传输和处理更加多样化,支持更完善的字符编码已经成为基础需求。开源社区和标准组织也在不断完善编码规范,致力于实现真正无障碍、跨语言的信息交流。用正确的编码方式传递信息,是实现全球互联互通的重要基石。
总的来说,文字乱码源于编码格式与解码方式的不一致,是历史遗留与技术发展交汇的产物。通过推广统一的Unicode编码标准,规范软件开发和内容发布流程,配合用户正确设置和使用,文字乱码问题能够得到显著缓解。理解并掌握文字编码基础知识,将有助于我们更好地处理数字文字信息,提升跨文化沟通效率和数字信息的准确传达。