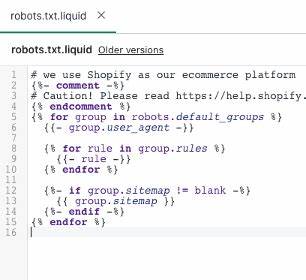
随着互联网电子商务的不断发展,Shopify作为全球领先的电商平台之一,一直致力于为卖家提供更优质的功能和更智能的管理工具。近期,Shopify对其店面默认的robots.txt文件进行了更新,这一举措引起了众多网站管理员和SEO优化人员的高度关注。了解和掌握robots.txt文件的作用及其最新更新内容,能够帮助电商店主更好地优化网站结构,提升搜索引擎排名,从而带动销售业绩的增长。 robots.txt文件是网站根目录下的重要文件,主要用于告诉搜索引擎的爬虫(如Googlebot、Bingbot等)哪些页面或目录可以抓取,哪些应当避免访问。合理配置robots.txt不仅可以有效保护隐私内容,防止无用或重复页面被索引,还能优化爬取频率,提升核心内容的抓取效率。根据行业惯例,许多电商平台通常会默认生成一份robots.txt文件,方便用户直接使用或者进行细微调整。
Shopify此次对默认robots.txt内容进行了优化,目的在于提升用户网站对搜索引擎的友好度及安全性。更新后的robots.txt文件,不仅细化了对后台管理页面、结账流程等敏感或无用页面的屏蔽,更灵活地开放了产品目录、博客页面、集合页等重要内容的抓取权限,确保这些页面能够被顺利收录和展示。这种更科学和精细的管理方式,有针对性地减少了搜索引擎因重复内容或爬取无关页面而带来的消耗,提升了整体网站权重的集中度。 对于广大Shopify店主来说,理解并善用最新的默认robots.txt规则至关重要。首先,默认配置在保证绝大部分电商功能正常发挥的前提下,极大简化了手动调整过程。对于SEO新手而言,这降低了出错风险,让他们能够更安心地投入内容建设、营销策划等核心工作中。
其次,若有特殊需求的进阶用户,也可以基于新的默认框架进行个性化定制,排除某些页面或目录的抓取权限,或者添加特定的爬虫指令,从而最大化地满足专业的SEO策略需求。 同时,Shopify的robots.txt更新也彰显了对电商安全及用户隐私的重视。在新的配置中,诸如后台登录页、客户数据页面、订单结算页等敏感内容均被明确禁止搜索引擎访问。这样的设定不仅防止了信息泄露风险,还避免了这些不宜公开展示页面被误判为垃圾页面而削弱网站整体质量评分。由此可见,Shopify正在积极构建一个更健康、更安全的电商生态环境。 对于SEO优化从业者来说,正确理解robots.txt的规则以及其更新的内容变化,有助于制定更科学的抓取策略。
例如,可以通过分析访问日志和抓取状态报告了解搜索引擎对网站访问的行为模式,发现可能存在的抓取瓶颈或资源浪费现象,及时调整robots.txt文件或配合使用sitemap.xml等辅助工具,提升检索效率和索引覆盖率。这种闭环优化机制是实现网站长远稳定增长的关键所在。 此外,更新后的默认robots.txt文件也体现了Shopify对多语言和移动端友好的支持。随着跨境电商的普及和移动购物的兴起,网站需要兼顾各种设备和语言的兼容性。新的robots.txt规则使得针对不同语言版本的页面和手机端特定资源的爬取权限更加明确和合理,使得相关内容能够及时被搜索引擎发现,帮助店铺扩大国际市场影响力并提升用户体验。 在实际应用中,电商企业还应结合robots.txt更新,持续优化网站内容质量、提升页面加载速度及完善内部链接结构,打造对搜索引擎算法尤其是Google Core Web Vitals等新标准友好的全方位优化环境。
良好的网站性能和用户体验配合合理的robots.txt管理,将极大提高自然流量和转化率。 总结而言,Shopify此次对默认robots.txt文件的更新,是其智能化电商管理和SEO优化服务迈出的重要一步。它不仅为中小卖家提供了便捷且安全的抓取管理方案,还有助于提升电商网站在搜索引擎中的可见度和排名稳定性。作为店铺运营者,积极关注并利用这一变化,配合整体的SEO策略调整,将为长期发展打下坚实基础。未来,随着搜索引擎规则的不断演进及电商平台的升级,理解和掌握robots.txt的相关知识将成为电商成功不可或缺的专业能力之一。