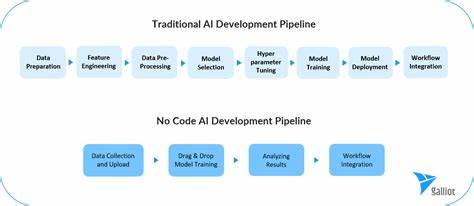
近年来,无代码数据科学工具从小众实验逐步走向主流,成为现代数据技术架构中不可或缺的组成部分。随着人工智能协作和自动化工作流程的兴起,2025年的无代码平台在数据分析、模型构建和结果展示中展现出极大潜力,使非专业程序员也能轻松驾驭复杂数据科学任务。然而,尽管市场需求旺盛,这类工具在实际应用中仍面临诸多挑战,限制了其广泛深化和拓展。无代码工具的最大优势在于降低了编程门槛,使得业务分析师、产品经理、市场人员甚至初级数据科学家得以自行探索数据、构建模型并实现数据可视化与报告。因此,传统的数据科学已不再专属于专业编程人才,而是脱离复杂代码束缚,向更广泛的用户群体开放。这意味着,工具不仅要提供直观的拖拽界面,更需结合智能辅助,实现对全流程的支持,涵盖数据导入、清洗、建模、评估与输出的闭环。
然而,现阶段无代码工具往往在简易性和功能丰富性之间陷入两难。一方面,若追求极致简单,平台可能牺牲定制化和扩展性,导致用户在遇到复杂场景时被限制,甚至不得不回归编程。另一方面,若功能过于复杂,初学者又可能因此望而却步,增加学习成本和流失率。如何在保持用户友好的同时,提供足够灵活且强大的特性,成为无代码平台亟待破解的难题。数据隐私与安全问题同样不容忽视。众多无代码工具依赖云端计算,要求用户将敏感数据上传至第三方服务器,这在金融、医疗、政府等受限行业尤其敏感。
合规性监管不断趋严,企业对于私有化部署、离线处理的需求日渐高涨,而传统的云端模型难以满足此类严格要求。因此,打造支持本地运行、离线操作的无代码工具成为未来发展趋势之一。例如,某些平台已支持全离线模式,避免数据泄露的安全风险,同时保持强大的功能表现,助力企业用户安心使用。另一个亟需解决的难题是教育和正确使用。由于操作门槛降低,非专业用户容易陷入误用风险,选用错误算法、误解分析结果的现象屡见不鲜。尽管工具内置简洁指引及部分自动化辅助,但实际应用中仍需更完善的实时反馈和智能校验机制,保障分析过程科学合理。
如何在保护用户使用体验的前提下,融入合适的学习资源和诊断功能,提升模型质量与结果可信度,是无代码工具未来技术创新的重点。闭环生态建设亦是目前的不足所在。部分平台将底层逻辑隐藏在专有界面,限制代码访问与导出,造成用户被生态绑定,难以审计、迁移或集成其他工具。开放性与兼容性不足,不利于构建长期可持续的数据科学工作流程。这不仅影响用户体验,也在企业级应用中带来运营风险。因此,未来无代码解决方案的核心正逐渐从单纯的简化操作,转移到如何实现代码与无代码的无缝融合,提供从自然语言到自动生成代码,再到手动调整与优化的混合模式,使用户在享受便捷的同时,仍能掌控模型的深度和精度。
尽管面临诸多挑战,无代码工具的未来发展依旧充满希望。随着人工智能技术深入融合,智能助理将在数据探索、异常检测、报告撰写等环节扮演日益主动的角色,推动分析流程自动化升级。同时,行业垂直化趋势明显,针对医疗、金融、零售等领域推出符合特定合规和业务需求的定制化无代码平台,将为企业提供更精准的解决方案。隐私优先的设计理念也将推动工具全面支持数据脱敏、匿名处理及私有AI模型嵌入,强化安全防护能力。更重要的是,未来无代码工具不仅是避免编写代码的助手,而是促进更高效、更智能思考的伙伴,帮助各类用户理解数据背后的故事,提升跨部门协作效率,支持快速构建和迭代数据驱动的解决方案。综上所述,无代码数据科学工具作为连接传统程序员和非技术业务群体的桥梁,正在经历从初级辅助向智能协同的转变。
开发者和厂商需要同时关注用户体验的简洁性和后台技术的开放性,兼顾数据安全及合规要求,促进教育培训和正确使用。唯有如此,才能真正释放无代码技术的潜能,推动数据科学的普及与应用深化,引领企业迈向智能化数据驱动未来。