近年来,随着人工智能技术的迅速发展,深度学习模型在计算机视觉、自然语言处理等多个领域取得了突破性进展。然而,伴随着模型性能的提升,模型的规模和复杂度也在不断膨胀,导致训练和部署成本显著上升。针对这一难题,模型蒸馏(Model Distillation)作为一种有效的模型压缩技术,通过从大型复杂模型中提取知识,训练出轻量级模型,广受研究者和工业界关注。DeepFabric作为该领域的创新平台,通过提供结构化的合成数据集,极大地促进了模型蒸馏的效率和效果,成为深度学习发展中的重要推动力量。 DeepFabric背后的核心理念是利用合成数据解决数据匮乏及隐私保护问题。在传统机器学习中,模型的训练往往依赖于大量标注数据,而高质量标注数据不仅获取成本高昂,而且存在敏感信息泄漏风险。
为此,DeepFabric通过构建高度结构化且可控的合成数据集,模拟真实数据的分布特征和多样性,使得训练模型能够在无须真实数据的条件下,达到甚至超越传统数据训练的效果。 相比于非结构化随机合成数据,DeepFabric的结构化方法允许研究人员精细控制数据的属性,例如特征相关性、样本类别比例及特定场景模拟等。这种定制化的数据生成不仅提高了数据的表达能力,还增强了模型对于复杂任务的泛化性能。此外,结构化合成数据在模型蒸馏过程中表现出优异的知识迁移能力,能够有效指导小型模型学习大模型的决策边界和特征表示,从而显著提升蒸馏模型的准确率和鲁棒性。 DeepFabric的应用场景广泛,在自动驾驶、医疗影像分析、智能制造等领域均展现出强大潜力。自动驾驶系统依赖于大量场景多样且高质量的感知数据,以保证车辆在复杂道路环境中的安全行驶。
传统数据采集过程不仅成本高昂,还可能受限于法律法规。利用DeepFabric合成数据,开发者能够快速生成涵盖不同光照、天气条件和交通状况的高仿真数据,有效训练和优化感知模型,同时降低数据收集风险。 医疗影像领域同样面临着数据隐私和样本不均衡的挑战。DeepFabric通过合成结构化的医学影像数据,帮助科研人员实现模型训练和验证,提升诊断系统的准确性和适应能力。同时,结构化合成数据可以补充少数特定疾病类别的样本,解决传统数据集中的类别偏差问题,从而支持更公平和全面的医疗AI系统建设。 在智能制造范畴,DeepFabric支持生成多维度、多模态的工业数据,用于设备故障预测和生产流程优化。
借助合成数据,企业能够模拟不同工况和异常情况,大幅提升模型适应性和预警能力,推动制造流程智能化升级。 DeepFabric平台的设计注重开放性和易用性,支持多种数据生成参数定制,兼容主流深度学习框架,方便开发者无缝集成至现有训练流程。其先进的数据生成模块利用先进的算法确保生成数据在统计特性和语义结构上的高度逼真,同时保持生成效率。此外,平台具备可扩展性,适应不同规模数据需求,为各种研究和应用场景提供支持。 从技术角度看,DeepFabric采用了生成对抗网络(GAN)、变分自编码器(VAE)等多种先进生成模型,结合领域知识嵌入和规则约束,实现了对数据多样性和结构复杂性的精准控制。其创新性的多阶段生成策略确保了数据质量和多模态一致性,显著提升了合成数据的实用价值。
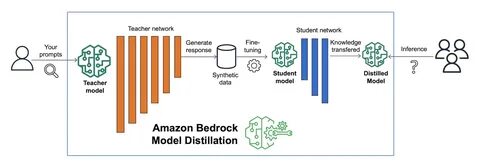
在模型蒸馏流程中,DeepFabric生成的结构化合成数据能够充当教师模型的补充训练集,丰富模型对关键特征的学习,同时避免过拟合真实数据。由此,小模型在蒸馏过程中不仅获得了更多样化的训练示例,也进一步掌握了复杂模型内隐的知识表达,从而在保证轻量化的前提下,实现高性能表现。 展望未来,随着人工智能对数据质量和数量的需求持续攀升,结构化合成数据技术的重要性必将日益凸显。DeepFabric通过创新的数据生成方法,为解决现实世界中数据难题提供了切实可行的解决方案。预计其在模型压缩、联邦学习、隐私保护等新兴领域也将发挥更大作用,推动人工智能技术迈向更高效、更安全的发展阶段。 综上所述,DeepFabric不仅是结构化合成数据集领域的领先者,更是推动模型蒸馏技术革新的重要力量。
其独特的数据生成技术和广泛的应用实践彰显了合成数据在未来人工智能生态中的巨大潜力,值得学术界和产业界持续关注与投入。通过深度融合合成数据与先进训练方法,DeepFabric正为构建更加智能、高效和可信的AI系统奠定坚实基础。 。