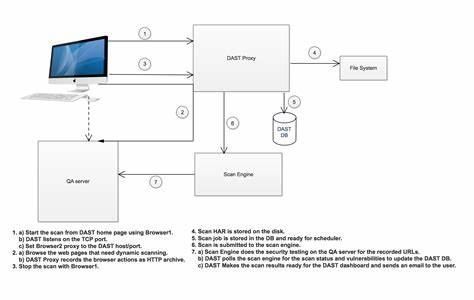
随着合成基因组学的兴起,定制合成DNA序列的需求迅速增加。技术进步使得合成核酸的成本显著下降,供应速度加快,从而极大促进了生物经济的发展。然而,这一同样属于双重用途技术的领域也伴随着潜在的安全风险,尤其是可能被用于有害目的的DNA序列。核酸合成供应商为了避免参与非法或危险生物制剂的制造,必须对客户订单中的核酸序列进行严格筛查,以检测是否包含受控、可能带来滥用风险的序列。然而,由于生物风险的多样性及风险定义的模糊,核酸筛查的准确度评估成为一大难题。 国际基因合成联盟(IGSC)成立了专门工作组,着力开发一个核酸合成筛查的原型测试集,期望通过标准化测试数据集来评估和比较各种筛查工具的表现,从而为该领域建立准确度基线。
该测试集聚焦于三个受控的生物分类集群,分别来自病毒(比如Orbivirus)、细菌(如Francisella tularensis)和真菌(Coccidioides)类群。筛查流程由四个不同的筛查工具独立执行,这些工具采用了多样的方法,包括基于序列比对、机器学习、k-mer特征筛选等先进算法,结合预设的分类体系,团队汇总并协调了来自不同工具的结果,解决了在基因注释和功能推断中出现的分歧。 这一测试过程揭示了多年来核酸筛查中存在的根本性挑战。不同筛查工具在判定受控序列时的保守程度和策略存在明显差异,一些工具采取“默认为有风险”,即只要存在潜在相似性就标记为风险;另一些则倾向“默认为无风险”,只在无法明确免除时才进行标记。这种策略上的差异,源自对多样化监管文件的不同理解,以及对科学证据不确定性的解读。这又使得筛查结果呈现出“无疑风险”、“无疑安全”及“状态不定”三分类,其中“状态不定”尤其体现出对于某些基因功能尚不明确、科学共识未达成的难题。
从测试结果来看,病毒群体中大部分核酸序列被一致标注为受控,显示病毒序列在识别上具有较高的一致性和确定性。而细菌和真菌序列则表现出更多的审慎与不确定性,尤其是在功能注释不完整或科学研究不足的区域。大量被归为“可选标记”类别的序列提示了我们对致病机制的理解仍有待深化,尤其是真核生物真菌的基因功能复杂多变,进一步增加了筛查的难度。此外,公共数据库中存在的注释错误、序列错标以及生物样品污染等问题,也让筛查工作面临挑战,亟需完善数据质量管理。 目前核酸筛查的多样性和复杂性也反映了合成DNA行业的多元需求。大型合成企业强调筛查的高通量和自动化,以应对海量订单,偏好减少误报以降低运营成本。
中小型企业则更关注风险规避的严谨性,希望减少潜在的安全隐患。正是这种需求上的差异,催生了多样化的筛查工具与策略。然而,在缺乏统一监管标准和权威认证机构的情况下,业界极需一个公认的标准测试集来衡量筛查工具的性能,实现方法论的优化和最佳实践的普及。 未来的发展方向不仅仅是扩大目前测试集的覆盖范围,涵盖IGSC监管路径数据库中所有39个受控生物集群和它们的近缘非控制物种,还要将筛查视角从单一物种转向基于功能的分类,评估那些即便不来自列管生物但已知与毒力或致病相关的基因和序列。此外,随着人工智能技术的迅速发展,机器学习和大规模语言模型正在成为预测序列功能、辅助筛查决策的重要工具,有望显著提升筛查的准确性和自动化水平,减少对人力专家的依赖。 为了实现上述目标,国际合作与多方参与是关键。
除了IGSC内部的跨领域协作,还需加强与政府监管机构如美国商务部工业与安全局(BIS)、国家标准与技术研究院(NIST)以及多边机制如澳大利亚集团(AG)等的联动,促进监管政策与技术手段的同步更新。推动对“状态不定”序列的统一分类评估及其相关法规解读,将极大提升全球核酸筛查的协调性和一致性,有助于形成更为高效和可持续的DNA合成安全监管环境。 综上所述,核酸筛查测试集的原型研制是实现精准、高效、安全DNA合成监管的重要一步。它不仅提升了不同筛查工具之间的比较和标准化能力,也深刻揭示了当前科学研究、数据库管理和法规体系中存在的短板和瓶颈。通过持续扩大测试集规模、强化国际合作、引入先进技术,未来的核酸筛查体系将更加完善,更具灵活性和前瞻性,助力生物技术健康发展,同时有效预防生物安全风险。2024年的这一进展为核酸筛查领域绘制了新的蓝图,开启了深度融合科学、技术与政策的全新时代。
。