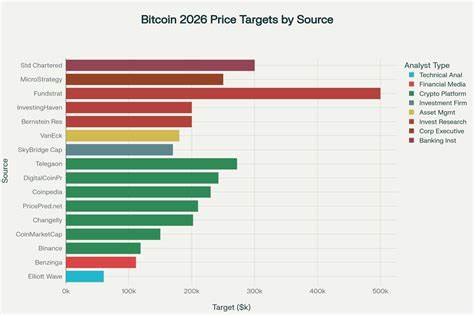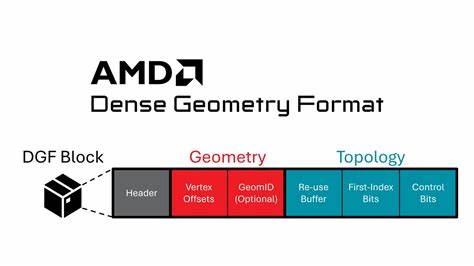
在实时渲染与光线追踪日益普及的今天,如何在保证高帧率的同时处理复杂几何体的动画成为关键问题。AMD 提出的 Dense Geometry Format(DGF)为压缩三角网格提供了硬件友好的块式表示,使得大规模几何数据在显存与带宽上更高效。更重要的是,随着对 DGF 的硬件支持愈加成熟,如何在不牺牲压缩收益的前提下实现动态几何体的高效更新,已经成为渲染工程中的重要研究方向。本文基于 AMD 官方 SDK 与最新博客内容,系统介绍如何使用 DGF 支持顶点动画和线性顶点混合(线性顶点 blend)、详细阐述烘焙调整、量化策略、运行时更新和性能考量,并给出实用建议,帮助开发者将 DGF 应用于真实项目中。 先从核心概念说起。DGF 的基本单位是 DGF-block,一个块最多包含 64 个顶点和 64 个三角形,整体以 128 字节为目标单元。
DGF 将网格划分为许多小的 meshlet,并对每个 meshlet 单独压缩。一个 DGF-block 内部包含三部分:头部信息、几何数据和拓扑数据。拓扑部分并不是传统的索引表,而是以一种广义的三角形带(包含回溯控制)来存储三角面连接关系,从而在索引成本上节省大量位数。几何部分关键在于以偏移量与锚点配合的量化表示:每个顶点并不直接存储浮点坐标,而是存储相对于块内锚点的无符号整数偏移,再乘以一个基于 2 的缩放因子得到浮点位置,整个缩放通过存储在头部的带偏移指数来表示。 理解 DGF 的几何表示对实现动画至关重要。DGF 每个块存储三个要素:锚点 A(以三个带符号 24 位整数表示),每个顶点的无符号整型偏移 Oi(每个通道采用块级别指定的位宽,1 到 16 位可选),以及一个缩放因子 2^{E-127}(E 存在头部,作为无符号字节偏置存储)。
最终的顶点浮点位置为 P_i = (A + O_i) * 2^{E-127}。为了避免网格开裂,AMD 的 DGF 烘焙器会精细地量化原始顶点到这些表示。然而在动画场景中,顶点会随时间改变,可能在空间上大幅移动或旋转,单帧的量化参数可能无法覆盖整个动画过程,因此需要在烘焙阶段对量化策略进行调整,以保证后续帧在写回 DGF-block 时不会因溢出而出错。 支持动画的核心思路是保留拓扑不变,仅更新 DGF-block 内的顶点偏移。常见的骨骼蒙皮(skinning)和形状混合(blend shape / morph target)都属于拓扑恒定、仅顶点位置随时间变化的范畴。实践中,流程分为静态烘焙阶段与运行时动画更新阶段。
静态烘焙阶段使用单帧拓扑(通常是休息位姿或关键帧之一)来生成 DGF-block 布局,但在生成块时为后续的顶点更新预留位置空间。运行时阶段负责根据关键帧数据或蒙皮结果在线生成动画顶点、对其量化并写回到 DGF-block,从而保证渲染与光线追踪直接读取到当前帧的压缩几何数据。 要实现上述流程,需要对 DGF 烘焙器(DGFBaker)进行少量但关键的配置调整。首先启用为动画量身定制的量化策略:将 config.quantizeForAnimations 设置为 true,使得烘焙器在选择指数 E 时基于簇的 AABB 对角线长度而不是各轴独立尺寸,这样能更稳健地应对旋转或整体移动导致的坐标扩展。其次采用 clusterDeformationPadding 参数给簇边界增加浮点倍数的填充,以容纳局部形变带来的伸展,从而进一步防止偏移溢出。第三,强制指定每个顶点通道的位宽,使用 blockForcedOffsetWidth 为 X、Y、Z 指定固定位数,而不是让烘焙器针对某一帧自适应位宽。
强制位宽可以保证所有关键帧及其插值帧都能在同一位预算内表示,避免某些帧写入失败或产生失真。样例支持 16/16/16、12/12/12、8/8/8 以及混合的 11/11/10 等常见选项。 另一个关键输出是 Vertex Table(顶点表)。DGF 烘焙器在划分 meshlet 时会复制并分散输入顶点到不同的 DGF-block,为了在运行时高效更新这些块而不必解压或重构块内顶点,设置 generateVertexTable 为 true 会输出一张映射表,映射 DGF-block 内的局部顶点索引到原始顶点数组的全局索引。这使得运行时只需对每个原始顶点做一次动画计算(例如骨骼变换或两个关键帧的线性插值),然后利用 Vertex Table 将量化后的结果散射写回各自的 DGF-block。为了写回时能够定位到全局顶点索引,建议启用 enableUserData,将 block 的用户数据区用于存储块偏移或其他必要信息,以便每个局部顶点能被正确映射。
运行时管线分为三个主要步骤:动画计算、量化与写回、渲染(包括 BVH 重建与光线追踪)。动画计算通常由计算着色器完成。着色器从所有关键帧数据中读取两个相邻关键帧的顶点位置与法线,通过线性插值或骨骼混合生成当前帧的浮点顶点结果。为了效率,示例中将所有关键帧顶点数据上传到 GPU 并在着色器中完成插值,生成一个 Animated Vertex Data 缓冲。为了避免重复计算,借助 Vertex Table 可以保证每个原始顶点只计算一次,即可通过散射操作更新其在多个 DGF-block 的副本。 量化与写回阶段同样使用计算着色器高效实现。
思路是以每个 DGF-block 为一个线程组,将整个 128 字节的块加载到组内共享内存(LDS)中进行原子位操作更新。由于固定的位宽可能导致多个顶点的数据共用一个 32 位字,为避免写冲突,需要使用原子与掩码操作(InterlockedAnd / InterlockedOr)来安全地清写与写入对应位段。量化过程包括将浮点位置乘以 2^{- (E-127)} 的逆(即应用未偏移的指数),得到整数化位置,然后利用组内波操作(如 WaveActiveMin)计算块内的最小值作为新的锚点。随后将每个偏移减去锚点并打包成 64 位码字,依据位偏移写回块内相应的位段。最后仅由波的第一个 lane 更新块头内的锚点字段,完成写回。AMD 的样例在硬件上表现出色:在 Radeon RX 7900 XT 上对 252K 三角形级别的场景,动画计算与量化写回合计只需几十微秒,远远小于 BVH 构建与光线追踪耗时。
性能与压缩效率之间存在权衡。固定位宽越大,单顶点的码长越长,会导致每个 DGF-block 容纳的顶点数减少,进而增加块数与总体存储开销,从而提高每三角形的字节密度。实验数据显示,将每通道设为 16 位时仍能相比未压缩数据节省显存,但压缩率不如 8 或 11/11/10 等更细粒度的设置。选择合适的位宽需要权衡动画幅度、期望的视觉保真度与总体内存预算。在目标是最小化内存占用的情况下,可以尝试将某些通道使用更少位宽或采用混合精度策略,而在动画范围大或变形剧烈的情况下,应优先保证足够的位宽以避免溢出与可见失真。 工程实现上有若干实用建议。
首先,尽量在烘焙阶段为簇选择保守的动画边界(AnimationExtents),如果提前已知关键帧或蒙皮范围,显式调用 BakerMesh::SetAnimationExtents 将大大降低运行时溢出的风险。如果动画范围未知,可使用休息位姿的包围盒加上安全系数作为近似。其次,合理设置 clusterDeformationPadding,可以用 1.03 到 1.2 的倍数来覆盖常见局部伸展。再次,生成 Vertex Table 并启用用户数据是支持高效运行时更新的关键,使更新过程避免重复变换与复杂的数据重构。最后,量化着色器中尽量利用波操作和 LDS 来减少内存访问,并用原子位操作保证并行写入的正确性。 从生态与未来趋势看,AMD 已为 DGF 提供了 Vulkan 扩展的初步支持,后续 GPU 架构将进一步提升对 DGF 的原生硬件支持,简化读取与压缩解码的开销。
对于实时光线追踪引擎而言,将几何压缩与动画更新纳入渲染管线可以显著降低显存使用并提高缓存效率,尤其适合需要同时渲染大量动态小物体或多实例动画的场景。DGF 的随机访问能力、块式更新机制以及与 BVH 构建相结合的工作流,使得实时重建加速结构和光线追踪在保持高质量输出的同时具备更好的扩展性。 结合实际项目的需求,可以将 DGF 与现有的资源管线和 LOD 系统配合使用。在内存受限的平台上,优先对高面数但细节不敏感的对象应用更激进的位宽压缩策略,而对面部、关键角色或近景对象使用较高位宽以保证视觉质量。对于混合渲染流程,动画顶点可以先在计算着色器中以半精度或压缩表示进行中间运算,然后仅在写回 DGF-block 时进行最终量化,从而减少临时带宽与缓存压力。 结论部分强调两个要点。
第一,DGF 提供了在保持拓扑不变前提下对几何动画进行高效压缩与更新的可行路径。通过在烘焙阶段设置动画友好的量化参数、生成 Vertex Table 并在运行时采用专用的量化写回着色器,工程师可以在几乎不影响帧时间的情况下完成大规模顶点更新。第二,压缩位宽与动画范围之间存在必要的权衡,合理配置 blockForcedOffsetWidth、quantizeForAnimations 与 clusterDeformationPadding 能在稳定性与压缩效率之间取得平衡。未来随着硬件对 DGF 的支持增强,基于 DGF 的动画管线将更广泛地应用于实时光线追踪、云渲染与高密度几何场景中。 如果你正在构建需要大量动态几何的渲染系统,建议下载最新的 AMD DGF SDK 样例,参考官方的 DGF 烘焙与运行时示例代码。实践中多尝试不同的位宽组合与簇填充系数,根据目标硬件与视觉门槛迭代配置。
采用 DGF 不仅能显著节省显存与带宽,还能让复杂场景的动画与光线追踪变得可扩展,赋能下一代实时渲染体验。 。