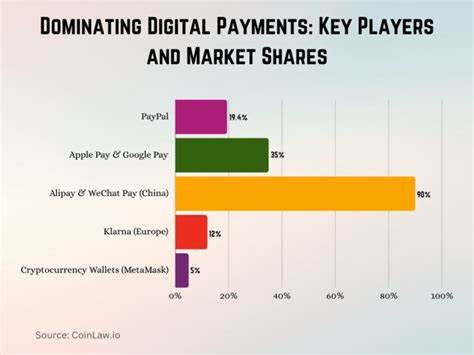
近年来,人工智能领域因大型语言模型(LLMs)的快速崛起而引发广泛关注。无论是在学术界还是产业界,庞大的模型规模似乎成为衡量技术先进性的唯一标准。然而,印度技术亿万富翁、Infosys联合创始人纳丹·尼莱克尼(Nandan Nilekani)却提出了不同的观点:未来的人工智能发展不应围绕谁打造出最大、最复杂的模型,而应聚焦于如何让人工智能真正服务于公众,解决现实生活中的具体问题。尼莱克尼是印度数字革命的关键人物,他设计并推动了覆盖14亿人口的数字身份系统Aadhaar,使印度民众能够便捷地使用银行、医疗、税务等多项数字服务。基于多年的经验,他呼吁全球重新思考AI的发展方向,强调规模不应成为唯一追求,实用性才是关键。尼莱克尼指出,当前全球有大量大型语言模型涌现,诸如美国的OpenAI、Gemini、Llama及Anthropic,及中国的DeepSeek和阿里巴巴的Qwen等。
在他看来,这些模型的构建很快会成为一种商品化的行为, 随着计算能力和数据资源的普及,构建模型将变得越来越普遍,模型本身不应成为人们执着的焦点。真正值得关注的是如何通过选取高质量、经过人工审核的数据,训练更小型、更高效、面向特定领域的模型。小型模型不仅成本低、推理速度快,而且能针对专门场景做出精准回应。这种趋势对于提升人工智能的普惠性和实用性尤为重要。尼莱克尼特别强调了语言技术在印度的必要性。印度拥有数百种语言和方言,传统的输入方式如键盘和触屏对完全文盲甚至半文盲的人群并不友好。
未来人工智能与人类交互将主要依赖语音,且需要支持地方语言和方言的自然表达。例如,印度比哈尔邦的农民若能用马伊提利语或博杰普里语与计算机交流,并获得准确答案,无疑极大提升了AI的可访问性。简言之,语音交互的本地化是扩大人工智能普及的重要突破口。此外,尼莱克尼提及,他支持印度理工学院马德拉斯分校的“AI for Bharat”项目,该项目并非依赖海量网络数据的爬取,而是在实地采集包含方言与地区口语的语音样本,形成了开放的、数据质量上乘的训练集。这种做法为训练有效的小模型树立了典范,能更好地反映真实使用场景的复杂性。关于大规模模型的“秘密性”问题,尼莱克尼表达了对大型科技公司日益垄断计算基础设施的担忧。
他认为,计算资源的高昂门槛不利于大众获取,应将分散的小型数据中心整合到一个共享的平台,实现计算资源的平等开放。如此,人工智能才能真正走进更广泛的用户群体,发挥更大社会价值。虽然尼莱克尼承认大型通用模型在某些领域有不可替代的优势,但他更强调灵活选用不同规模模型的必要性:有些场景适合部署中小型模型,甚至在用户手机端运行的量化模型,这不仅节省计算资源,也提升响应速度和隐私保护。展望全球人工智能的竞争格局,尼莱克尼正视中美两国在AI建模上的激烈角逐,但认为这场竞赛反而促进了全球技术创新的加速。他鼓励共享和开源精神,认为模型技术一旦变为商品,任何有足够算力和优质数据的人都能参与构建,科技不应被少数巨头垄断。从历史角度看,技术发展总经历多个周期,曾经经历过互联网泡沫、Web3、加密货币、元宇宙等热点起落。
AI同样既存在炒作成分,也蕴含真正的变革力量。关键在于如何谨慎管理风险,确保技术以负责任的方式赋能社会。总结而言,全球不应再盲目追逐大型语言模型的规模竞赛。人工智能的未来应聚焦于从小做起,打造高效、专用、符合多样化需求的模型,提升实际应用的价值。通过开放协作,惠及更多语言和文化群体,推动技术普惠,让技术发展真正回归服务民生的本质。只有这样,人工智能才能成为改变世界的真正力量,而非简单的技术噱头。
。