在开源世界里,curl 是一个备受信赖的网络库,其维护者 Daniel Stenberg 的一条公开说明引发了对 AI 辅助漏洞报告价值与成本的广泛讨论。近期安全研究者 Joshua Rogers 使用一系列 AI 辅助的静态应用安全测试工具(SAST)对 curl 进行了扫描,并提交了大量潜在问题的 SARIF 数据。Stenberg 在社交平台上公开表示,这些扫描带来了切实的成果:迄今已修复至少二十二个 bug,还有更多需要人工审核的项点。这一动态既体现了 AI 工具在专业手中的增强能力,也揭示了对开源维护者造成的现实压力。 这次事件的重要性不仅在于发现了具体的错误,还在于它成为了讨论 AI 辅助安全工具成熟度和实际可用性的一个案例样本。Joshua 所用工具包括 Almanax、Amplify Security、Corgea、Gecko Security 和 ZeroPath 等,这些工具将大量检测结果以 SARIF 格式导出,方便自动化集成和批量审查。
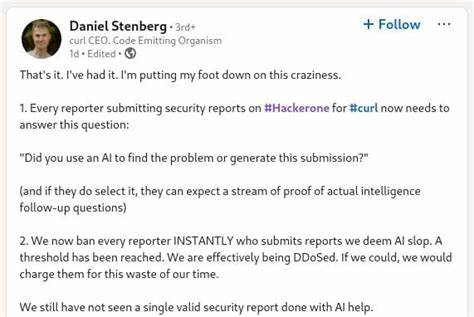
对于像 curl 这样代码基数大、历史悠久的项目,自动化检测能在短时间内暴露许多边缘情况或编程风格问题,从而帮助维护者找到长期未察觉的问题。与此同时,大量的误报和噪音也会吞噬维护者的时间,造成类 DDoS 的体验。Stenberg 早在 HackerOne 上就表示过对所谓"AI slop"报告的担忧,他指出在缺乏有效人工筛查的情况下,项目会被大量低价值报告淹没,最终不得不对来源采取封禁措施。此番 Joshua 的工作在某种程度上验证了 Stenberg 的观点:AI 工具能产出高价值成果,但前提是有经验丰富的人来解读与筛选结果。 从技术层面看,AI 辅助的 SAST 并不是简单的"黑箱出结论"。这些工具通常将静态分析器、模式匹配器和基于大模型的推理结合使用,试图在代码路径、内存管理、边界检查和错误处理等方面发现异常。
它们能识别常见的编程失误,也能通过学习大量开源修复样本推断出潜在危险模式。SARIF 作为通用结果格式,帮助研究者打包扫描发现以便复现与追踪,这对漏洞修复流程非常重要。Joshua 将扫描结果归档并提供给 curl 团队,方便维护者逐项处理,这是一次典型的"人机协作"流程:自动工具负责大规模检测和优先级排序,人工工程师负责验证、复现与修补。 然而问题在于,现阶段许多 AI 驱动的检测仍然会产生大量误报。误报来源有多种:静态分析器在缺乏运行时上下文时常常把合法代码误判为风险;基于训练数据的模型可能因样本偏差而放大某类模式;LLM 在生成漏洞描述或修复建议时可能出现"幻觉",提供无法复现或错误的修复路径。对于开源维护者而言,评估这些报告的成本不亚于修复真正的 bug。
Stenberg 的早期立场是为了保护有限的维护资源,他选择对那些显然由 AI 批量生成且未经过基本人工筛查的报告采取严格措施。这样的防御性做法是对维护时间与注意力的一种保护,但同时也可能错过那些高质量但呈现形式不合规范的贡献。 Joshua 的成功恰恰展示了一个重要原则:AI 工具的产出质量在很大程度上取决于操作者的专业能力。一个经验丰富的安全工程师能够设计合理的扫描策略、过滤噪音、验证可利用性并把发现以有用的格式提交给维护者。Stenberg 在另一则公开评论中指出,若在工具使用中加入"微小但智能的人工检查",结果会显著改善。这个观点的内核是明确的:AI 不应当被视为替代人类专家的万能方案,而应作为放大专家能力的工具。
专业人员能够分辨哪些问题值得立即修复,哪些属于风格或静态分析假阳性,从而把有限的维护资源用于最需要的地方。 对开源生态来说,要在鼓励贡献与保护维护者之间找到平衡并不容易。维护者希望接收到高质量、可复现且包含最小可行示例(minimal reproducible example)的漏洞报告;研究者希望工具能放大他们的效率;工具供应商希望展示模型的发现能力并获取客户。为缓解冲突,各方可以考虑几种改进方向。首先,研究者在提交 AI 辅助的发现时应包含尽可能多的上下文信息,包括复现步骤、受影响的版本范围、SARIF 导出的原始信息和一段人工撰写的验证说明。这样的额外信息能极大降低维护者的审查成本。
其次,工具厂商应加强误报抑制策略,改进阈值控制并提供更明确的置信度指标,以便研究者和维护者更好地评估结果的可信度。 此外,社区层面的制度创新也值得考虑。项目可以在贡献指南中增加针对 AI 辅助发现的接收标准,说明如何提交包含 SARIF 的检测包、必须的验证步骤以及期望的修复建议格式。安全平台和漏洞赏金平台也可以在规则中明确区分人工发现与 AI 辅助发现,设立针对性审核机制,并鼓励提交者在初次上传前进行基本人工把关。这样既能鼓励利用先进工具提升漏洞挖掘效率,也能避免维护者被大量低效输入淹没。 从法律与伦理视角出发,AI 辅助扫描带来的报告若包含大量自动化生成内容,也可能触发责任和归属争议。
谁对误报引起的影响负责?若工具建议的修复方案带来回归或新的安全问题,工具提供方是否需要承担一定解释义务?这些问题在当前缺乏统一规范的情况下难以得到明确答案。开源社区在处理此类问题时,往往依赖于社会规范而非法律条文,因此维护者的实践经验和公开记录就显得尤为重要。像 Stenberg 这样的维护者通过明确沟通他们的验收门槛与处理流程,既保护了项目的健康,也为社区设立了可借鉴的范例。 技术上,提升 AI 工具的实用性可以从几个方向并行推进。改进模型训练数据的多样性和质量,加入更多的真实修复案例和负样本,能降低模型生成的幻觉率。结合轻量级动态分析或模糊测试结果可以提供运行时证据,显著提高检测可信度。
工具应进一步采用可解释性的机制,向使用者展示检测结论背后的推理路径与证据链,帮助人类理解为何一段代码被标记为潜在问题。最后,加强与开源项目的集成,例如通过 CI/CD 插件、可选的扫描规则集以及与维护者协商的报告格式,能在来源和质控上形成闭环。 对于安全研究者与工程师而言,AI 是效率提升的工具,但能否真正助力取决于方法论。有效的实践包括事前设计好扫描范围、设定合理的置信度阈值、对关键发现进行人工复现、在提交中附上最小可复现示例以及明确受影响版本。这样的举动不仅能提高被采纳的概率,还能减少维护者的摩擦,从而在长远中建立信任关系。Joshua Rogers 的工作正是这一工作流的体现:他没有仅仅依赖机器输出,而是将机器发现包装成可操作的格式,并让维护者能逐项处理。
对普通开发者与用户来说,这次讨论也具有现实意义。它提醒我们当下许多安全发现仍然需要人类的判断。AI 可以发现代码模式中的异常,但洞察系统性风险、评估攻击链可能性以及权衡修复代价往往需要工程师的背景知识和经验。用户和企业在评估第三方库风险时,应关注维护者的响应机制和项目的健康状态,而不是单纯依赖自动化扫描报告。维护者能否及时修复问题、社区是否能提供补丁和回滚方案,才是衡量依赖风险的关键指标。 回到 Stenberg 的核心观点:AI 工具最有价值的使用场景是当专业人士用它们来放大已有能力,而不是让未经筛查的自动报告直接淹没维护流程。
Joshua 所带来的 22 个已修复问题是对这一观点的正面印证。同时,剩余的大量待审查项提醒我们,技术进步必须配合流程与制度创新,才能真正把自动化检测的潜力变成可持续的安全改进。开源生态需要工具厂商、研究者与维护者三方协作,建立清晰的提交规范、增强检测的可解释性并改良误报控制。 总结来看,AI 辅助的静态安全检测在发现问题的速度和覆盖面上展现出巨大潜力,但其价值最大程度地体现取决于人的参与与流程设计。对于像 curl 这样的关键开源项目,既不能完全排斥 AI 的贡献,也不能忽视由自动化带来的审查负担。通过明确的提交标准、工具能力的透明化、以及对人工复现和解释的重视,社区可以把 AI 从噪音源转变为提升安全性的加速器。
Daniel Stenberg 的公开反应和 Joshua Rogers 的实践为开源安全提供了重要的经验样本,值得维护者和工具开发者认真借鉴并在未来不断优化协作方式。 。