随着大数据时代的到来,如何高效处理、分析和可视化海量数据已成为行业发展的重要课题。面对数据量激增和实时流数据的挑战,传统的可视化工具和分析平台往往难以兼顾性能与交互体验。就在此背景下,Perspective作为一个专门面向大规模和流式数据的交互式数据可视化与分析组件,迅速崭露头角,成为众多开发者、数据科学家和企业的首选解决方案。Perspective凭借其强大的性能、安全高效的引擎设计、灵活的使用场景以及友好的开发体验,正在推动数据分析方法的革新。首先,Perspective之所以能够轻松应对大数据处理,得益于其底层采用了C++编写的高效流式查询引擎。该引擎不仅拥有极佳的计算速度,还通过编译为WebAssembly实现前端浏览器高性能运算,大大减轻服务器压力,提升了客户端的响应速度。
内置的高性能列式表达式语言基于ExprTK,使得复杂的列数据操作和即时查询更为便捷,进一步增强了数据交互的灵活性。在数据存储与传输方面,Perspective支持Apache Arrow格式,确保数据序列化和内存使用的最大优化。无论是批量数据加载还是流数据更新,都能保证高效且稳定的运行,满足实时分析需求。另一方面,从用户体验角度来看,Perspective提供了基于自定义元素(Custom Elements)的前端用户界面,无论是单纯浏览器端运行还是通过Python和Node.js搭建的WebSocket服务器架构,都能无缝对接。此外,集成在JupyterLab中的Perspective小部件,为数据科学家和研究人员提供了交互式的分析环境,可以直接在笔记本中动态操作Pandas数据结构和Apache Arrow数据,极大地简化了数据探索与洞察流程。开发者通过JavaScript API能够轻松创建互动性强、配置灵活的数据仪表板和报表。
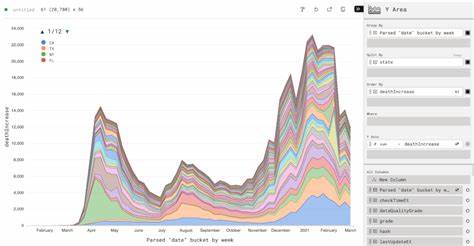
凭借Perspective的查询语言,可以对数据视图进行跨过滤、导出、复制以及保存操作。各个数据视图之间还能实现联动,提升信息挖掘效率并支持多维度分析。支持将工作空间状态序列化,实现数据视图的持久化和复现,便于协同和后续查看。对大型真实数据集的支持尤为突出,服务器端虚拟化模式仅按需传输当前视图所需数据,确保应用加载迅速且不会出现卡顿。通过Apache Arrow实现与WebAssembly的数据高效流交互,轻松达到数百万乃至更多行级别的数据访问,满足企业对大规模数据展示的需求。在Python生态体系中,perspective-python库为生产环境提供了虚拟化的高性能服务器,也支持研究环境中直接嵌入JupyterLab完成交互任务。
它兼容Pandas和Arrow格式,降低了复杂数据结构的使用门槛,同时借助后端服务器加速计算,有力支持了业务场景下海量数据的实时分析和决策。Perspective在实际项目中的应用场景十分广泛。从金融市场实时行情监测及预警,到物联网设备状态的流数据分析,再到电子商务推荐系统的多维度数据展现,无不体现出其在高吞吐量和动态数据环境下的优势。企业凭借其灵活的部署模型,可以选择纯浏览器端执行以方便快速监听数据变化,也可以结合Python后端架构实现更复杂的业务逻辑处理。相比于传统BI工具和数据可视化平台,Perspective的优势在于其真正做到内存高效和计算快速,让大数据不再是交互式分析的瓶颈。结合其易用的编程接口和配套的组件生态,开发人员可以自由搭建符合业务需求的定制化分析仪表盘,大幅提升开发效率。
总的来说,Perspective不仅是一个强大的数据可视化和分析组件,更是对大数据处理理念的创新体现。它将底层高性能引擎与灵活的前端交互无缝融合,为用户带来流畅、高效且智能的数据探索体验。随着开源社区的不断完善和功能的持续扩展,Perspective未来有望广泛应用于更多行业领域,推动数据驱动决策的普及和进步。无论是面向研究型数据分析,还是面向生产环境的实时大数据可视化,Perspective都能提供强有力的技术支持,助力用户释放数据的真正价值。对于数据从业者来说,掌握和应用Perspective,无疑是顺应技术趋势,提升数据竞争力的重要一步。