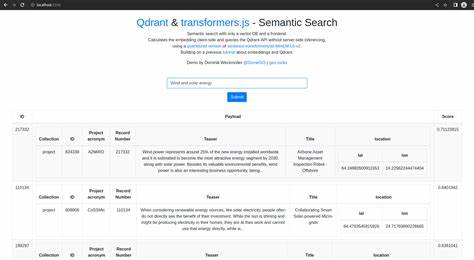
随着人工智能技术的飞速发展,语义搜索逐渐成为信息检索领域的重要方向。传统的语义搜索通常依赖服务器端进行复杂的模型推断,既造成了部署成本高昂,也存在一定的隐私风险。而transformers.js的出现,则为前端实时语义搜索带来了全新的可能性,实现了无需服务器参与、数据本地处理的高效检索体验。 transformers.js是一个基于JavaScript的自然语言处理库,支持多种Transformer模型的加载与运行,能够在浏览器环境中完成文本向量化的计算。通过将文本转换为语义向量,结合余弦相似度等算法,用户可以直接在浏览器端对文档进行语义级别的匹配和检索,保证了数据的私密性并提升了响应速度。 这种前端语义搜索的实现并非空中楼阁。
transformers.js通过WebAssembly和WebGPU技术优化了计算性能,使得即使是大型文本库也能在几秒内完成索引和检索。以经典文学作品为例,《圣经》《悲惨世界》《资本论》等多语种文档均可在浏览器中快速构建索引,支持按语义相关度快速搜索目标内容。这种方式鼓励用户直接在本地操作,无需上传敏感数据到服务器,极大增强了用户隐私保护的保障。 用户体验方面,transformers.js提供了灵活的检索参数调整能力。用户可以根据自身需求调节文本分块大小,实现对检索精度和速度的权衡。更细粒度的分块适用于对文本含义进行精确的定位,而大尺寸的分块则适合快速筛选海量信息。
诸如PDF页面、网页内容等多样文档类型均能被加载分析,为不同场景提供了广泛的适配性。 此外,系统还支持基于降维技术的语义可视化,通过快速的tSNE算法展示文本向量的聚类关系,帮助用户直观理解文档和检索结果之间的语义距离。这样的交互设计不仅提升了检索的趣味性,也有助于进一步优化搜索策略。 该解决方案同样具备极高的扩展性。开发者和用户可贡献自建的语义索引库,分享给更广泛的社区,推动多语言、多领域的文本资源实现语义检索功能。与此同时,前端技术的不断进步也预示着更强大的Transformer模型将陆续集成进浏览器环境,带来更精准、更智能的检索效果。
面对日益增长的文本数据和重视隐私保护的趋势,前端实时语义搜索无疑代表了信息检索的未来方向。transformers.js作为这一浪潮中的先锋,不仅降低了部署门槛,也使语义搜索技术惠及更多用户。无论是教育研究、内容创作还是企业智能办公,均能充分发挥其优势,提高效率与安全性。 未来,随着硬件性能的提升和算法优化,前端语义搜索的响应速度与模型复杂度将持续提升。结合本地缓存及离线使用模式,这一技术还将扩大其应用边界,覆盖无网络环境和边缘计算需求。同时,跨平台的兼容性亦将进一步改善,让更多设备和浏览器都能流畅承载复杂的自然语言理解任务。
总结来看,transformers.js所实现的前端实时语义搜索,打破了传统服务器依赖的限制,为用户提供了私密高效的检索体验。通过先进的向量计算和智能匹配技术,将深度语义理解带入每个人的浏览器中,开创了智能搜索的新纪元。对于希望提升内容查找效率、保障数据安全的各类用户和开发者而言,这是一项值得深入探索和广泛应用的前沿技术。 。