随着人工智能技术的迅猛发展,特别是大型语言模型(Large Language Models,简称LLMs)的崛起,我们对机器理解与推理自然语言的期待不断提升。从早期的语法分析,到如今高度复杂的上下文理解,LLMs在各种语言任务中表现出了接近人类的能力,甚至在某些领域超越了人类。然而,尽管这些模型在表面上的语言生成能力极为强大,其对底层逻辑推理和规则的掌握仍然存在明显不足。本文聚焦于关于大型语言模型能否有效推理规则的核心问题,结合前沿研究思路中的逻辑脚手架概念,展开深入分析。人类在推理时,依赖于抽象的推断规则,这些规则不仅帮助我们快速理解复杂关系,也使我们能够在未曾见过的场景中灵活应用已有知识。与此相比,现阶段的LLMs虽具备庞大的知识储备与语言生成能力,却难以像人类一样稳健地抽象并推演出隐含的逻辑关系。
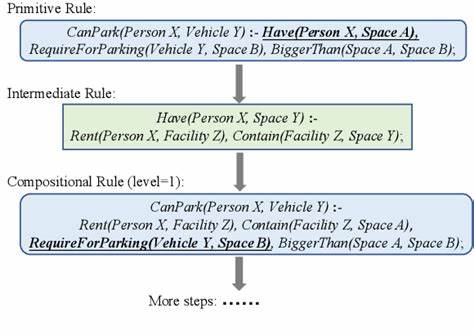
近期发表的研究提出了一种创新的“逻辑脚手架”推断规则生成框架,试图系统地构建涵盖多个领域的可组合推理规则库——ULogic。该框架设计初衷是通过符号逻辑的形式结构,辅助大型语言模型进行压力测试,深度挖掘其在推理复杂及结构化规则时的表现极限。ULogic不仅包括了基础的推断规则,还进一步覆盖了由基础规则组合而成的复杂规则,达到对模型推理能力从简单到复杂的层层考验。实验结果显示,现有的GPT系列模型在基于ULogic的测试规则集上与人类表现存在显著差距。当问题涉及多层次的条件组合和更深层的逻辑结构时,模型的误判和不确定性明显增加,尤其在面对带有偏见模式的推理情境下,错误率提升更加显著。这一发现提醒我们,要真正实现具备人类水平推理能力的人工智能,单纯依靠大规模的语料输入和统计模式学习是不够的,而需要引入更严谨的逻辑引擎和知识结构。
在实际应用层面,为了弥补大型语言模型的不足,研究团队进一步基于这些推断规则开发了一个小规模的推理引擎,可灵活生成推理规则并辅助下游的推理任务。该引擎不仅能够自动生成准确而复杂的结论与前提,还成功提升了多项常识推理任务的表现,体现出符号逻辑与深度学习相结合的新思路的巨大潜力。逻辑脚手架技术的应用为我们提供了一个明确的评判标准,用以检测和分析语言模型在规则推理方面的弱点和不足。这种技术不仅为模型的设计与改进指明方向,还创造了一个可控、可拓展的推理测试环境,有利于推动未来模型架构的革新。当前,LLMs在处理语义理解和模糊语言信息方面取得了令人瞩目的成就,但其在严密的逻辑推理方面仍然表现出脆弱性,这在处理诸如法律推理、科学推断以及复杂的策略游戏时尤为突出。传统的符号逻辑方法强调规则的明确性与推理过程的可解释性,但其灵活性和扩展性有限。
LLMs则具有强大的模式学习能力和语言生成能力,但丧失了对符号规则的透明掌控。将这两者结合,构筑逻辑脚手架,成为当前研究的热点和难点。此外,理解LLMs在推理规则上的局限性,也对生成可信赖、可解释的人工智能系统提出了新的需求。无论是自动问答、智能辅助决策还是复杂任务自动化,只有当模型能够准确、清晰地根据逻辑规则推理,才能确保其输出的正确性和有效性。未来的发展趋势或将集中在增强模型对符号推理的敏感度和能力,强化规则生成的自动化和动态更新机制,提升模型面对非结构化与结构化信息时的推理一致性。人工智能社区越来越多地关注将符号推理与神经网络方法深度融合的混合智能体系,逻辑脚手架的提出无疑为这一目标提供了重要支撑。
结合可解释性,可靠性与灵活性,逻辑脚手架不仅可作为评估和提升语言模型推理能力的工具,还可能成为科研与实际应用中构建更智能、更人性化系统的基石。综上所述,大型语言模型目前虽然在自然语言处理领域表现杰出,但在规则推理的准确性与深度方面仍存在瓶颈。逻辑脚手架作为一种创新的方法,利用符号化的推理规则结构进行压力测试和能力提升,开辟了全新路径。随着技术的不断进步,我们有理由期待结合逻辑推理框架的语言模型,能够在不久的将来实现更为稳定、透明且强大的推理能力,引领人工智能向真正理解和推理的智能时代迈进。