人工智能领域近年来在视觉语言模型(Vision-Language Models, VLMs)的发展上取得了突破性进展,尤其是在图像理解与语言生成的交叉领域表现出色。然而,当前VLM在空间感知与具身认知能力上仍然存在显著短板,限制了其在机器人操控和复杂环境交互中的应用。所谓具身空间,是指具身智能系统能够在真实或模拟环境中,通过感官输入和执行动作实现理解和反馈的能力。由此,推动视觉语言模型向具身空间方向转型,成为推动人工智能走向通用智能的关键一环。 传统的视觉语言模型主要通过大规模图像与文本数据预训练,使模型学会在静态场景中理解和描述视觉信息。但这些预训练分布往往与具身环境中的动态、交互式特性存在本质差异,比如动作生成、空间导航、目标分解等复杂任务均难以胜任。
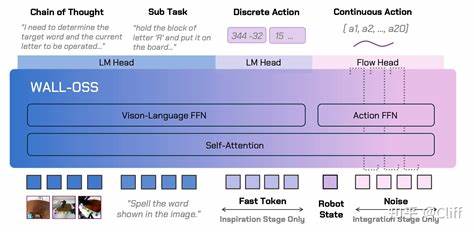
面对这些挑战,研究人员提出了新型的模型架构和训练策略,试图缩小视觉、语言与动作之间的鸿沟。 近期发布的WALL-OSS模型正是这一方向上的典型代表。该模型以端到端的多模态大规模预训练为基础,兼顾了具身环境中对空间认知和动作执行的需求。其核心设计理念在于实现高度耦合的视觉语言理解与行动能力,以保证模型能够理解复杂的指令、分解任务目标,并生成细粒度的动作序列。 WALL-OSS采用了一种统一的跨层连锁思维(Unified Cross-Level CoT)机制,将指令推理、子目标拆分与具体动作合成为单一的可微分框架。这种设计不仅提升了模型执行长周期操作的成功率,也增强了其对复杂环境的适应性和灵活性。
实验结果表明,该模型在多阶段、多目标的操控任务中表现优异,远超现有同类基线模型。 具身空间的智能系统需要做到的不仅是识别和理解物体,还包括理解环境中的空间关系、动态变化和因果联系。视觉语言模型必须突破传统"被动观察"的范畴,转而主动感知和交互,从而在真实世界中执行有效的操作。为实现这一目标,研究者不仅强化了多模态数据的预训练,还引入了多策略训练课程,通过模拟现实环境中的复杂场景,逐步提升模型的行动规划与执行能力。 这一转变对推动服务机器人、智能助理乃至自动驾驶和工业自动化领域的发展意义深远。通过赋予机器人和智能体具身感知与操作能力,未来它们将能够更好地理解用户的指令意图,完成更为复杂和连贯的任务,进而实现真正的智能协作。
然而,踏入具身空间的道路依然充满挑战。视觉语言模型需要解决多模态信息的深度融合问题,有效处理图像、视频、语言和动作信号的异构特性。同时,模型还要克服现实环境中的不确定性与噪声干扰,具备实时响应与自适应调整能力。此外,如何设计高效且可扩展的训练框架,使得大型模型能够在复杂环境下持续学习和优化,也是研究重点之一。 展望未来,点燃视觉语言模型走向具身空间的创新将推动人工智能从静态感知迈向动态认知,实现从理解到行动的无缝连接。基于多模态深度学习的全新架构正在开辟更广阔的发展空间,协助智能体突破奠基于数据的限制,迈向具有人类般感知与操作能力的新高度。
随着相关技术的成熟,具身智能将为智慧家庭、医疗护理、工业生产以及自动驾驶等多个领域带来革命性影响,促进社会与科技的深度融合。 总结而言,视觉语言模型的具身化转型代表了人工智能研究中的一个重要里程碑。通过整合视觉、语言与动作的跨模态能力,未来的智能系统将不仅能"看懂"世界,更能"动起来",结合认知与行为,实现真正意义上的全面智能。这一趋势无疑将引领人工智能进入一个更加智慧和实用的新时代,不断推动技术边界的拓展,为人类生活和生产方式带来深远变革。 。