在当今数字化时代,用户数据成为企业最为重要的资产之一。随着业务规模的不断扩大或系统升级改造,数据迁移成为一项极为关键且复杂的工作。尤其是当需要在没有停机时间和数据丢失的前提下,完成数百万甚至数千万用户数据的迁移时,这一挑战尤为艰巨。借助开源工具Debezium和消息中间件Apache Kafka,结合定制的同步算法,企业能够在保障数据一致性和系统高可用性的同时,实现复杂的用户数据迁移。本文深入解析基于Debezium和Kafka的用户数据迁移方案的设计思路、技术难点及解决方案,旨在为相关领域的工程师和技术决策者提供切实可行的指导。 用户数据迁移的背景和挑战 以德国领先再营销平台Kleinanzeigen(KA)为例,其拥有逾三千三百万独立访客的庞大用户群,对平台的依赖极高。
KA为了迁移至全新技术架构,同时避免传统大爆炸式迁移带来的巨大风险,采用了平滑切换策略,在新旧系统并行运行的模式下逐步迁移用户数据。 用户数据迁移涉及用户身份信息、个人资料、广告、交易及消息等多个模块,相互之间存在严格的依赖关系。因此,迁移顺序必须经过精心协调,确保所有数据依赖得到满足。例如,广告数据无法脱离用户信息独立存在,先迁移广告会导致数据关联失败。如何合理安排迁移顺序是一大难点。 初期架构设计与技术选型 考虑到系统复杂性,团队利用反向代理拦截和转发用户请求,在确保仍有用户访问旧系统的同时,逐步将已迁移用户通过代理引导至新系统。
此方案架构中,异步消息传递代替了同步双写,以避免网络波动和链路中断引发的写入不一致。 同步机制的挑战在于一旦旧系统的写入成功而新系统失败或反之,必须额外构建事务补偿机制如Saga,复杂度大幅提升。KA判断最终业务可接受系统间微弱的延迟,倾向于保证系统的高可用性和可维护性。 与此同时,数据转换需求也不容忽视。技术债务积累导致部分用户数据格式及字段存在冗余或非规范,为统一新平台标准,必须在迁移流程中增设转换环节。该实现若放在旧系统复杂代码中,改造难度极大;若放在新系统,则需跨团队协调,效率低下。
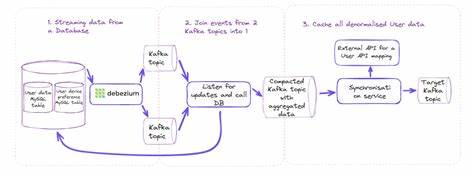
因此,将转换逻辑植入集中同步服务成为核心策略之一。 从传统事务出发的变革——为何选择CDC 传统的事务出站口(Transactional Outbox)方案虽然广泛应用于数据同步,但由于涉及轮询数据库事件表,无法支持KA亿级用户及百万级日更新量的高吞吐需求。且实施时容易出现事件排序错误和数据遗漏,导致长尾一致性问题和维护负担加重。 更重要的是,旧系统施改位置错综复杂,埋点难度和覆盖盲区风险极大。为此,KA转向借助变更数据捕获(Change Data Capture,简称CDC)技术直接监听数据库变更日志,进而实现对所有更改的实时、无遗漏捕获和推送。 Debezium作为开源CDC平台,具有连接MySQL Binlog的能力,能够准确捕获数据库事务后的数据变更,并将其以事件流的形式输出至Kafka主题,天然契合大规模数据同步场景。
KA团队经过调研后决定尝试引入Debezium,以期提升迁移流程的可靠性和扩展性。 实际部署中的技术难题及解决方案 KA的MySQL集群采用单主多从架构,多个数据中心部署主备,其中主节点Binlog配置为语句级(Statement-based)格式,且未启用全局事务ID(GTID),给CDC部署带来了挑战。Debezium依赖Row-based格式的Binlog和GTID以确保读取一致性及自动故障切换。 鉴于大规模改动影响生产稳定,团队采用折中方案,新增两个具备Row-based日志格式的MySQL实例作为从库,并通过反向代理控制访问,Debezium只跟踪这两个示例之一。若实例故障,通过代理切换后重启Debezium并重建配置主题,保证连续性。为防止丢失变更,设置Binlog保留时间至少七天,同时利用Debezium的快照功能在必要时补充同步未捕获的数据。
以上架构赋予了团队可控又灵活的变更监听能力,避免了对整个生产MySQL集群的改造风险,为后续迁移奠定基础。 状态机驱动的迁移过程管理 用户迁移不仅要确保数据同步,更需实时追踪迁移进度,支持分批抽样、回滚及阶段推进。团队借鉴移民流程模型,设计了五态状态机——识别(IDENTIFIED)、可迁移(ELIGIBLE)、迁移请求(MIGRATION_REQUESTED)、迁移完成(MIGRATED)和切换(TRANSITIONED),准确反映用户从识别到正式切换新平台的全过程。 该状态信息以“移民者”(Emigrant)实体存在于旧系统数据库中,避免对用户核心数据产生干扰。顺序性的状态机设计确保迁移流程的有序执行。通过Debezium监听Emigrant的状态变更,触发相应的迁移操作,实现自动化的流水线式迁移管理。
一旦用户状态从IDENTIFIED更新为ELIGIBLE,即判定用户数据满足转换标准并进入迁移队列。系统触发HTTP请求调用新系统API创建账户,成功后更新状态为MIGRATION_REQUESTED,迁移过程中持续同步变更。迁移完成后进一步标记为MIGRATED,最后通过管理服务决定是否将流量切换至新平台,完成TRANSITIONED阶段。 迁移流程全链路的可靠性保证得益于数据库事务结合CDC事件的原子性,极大降低了消息丢失的风险,也让失败重试变得高效而安全。 双向更新与无限循环的终结之道 在实际业务中,用户数据并非严格单向更新。迁移过程中,部分场景需要在切换后依然同步旧系统的数据变更,如密码重置或账号封禁。
这种双向更新如无防护易引发同步死循环,使得数据不断重复修改,系统负载剧增。 为破解这一难题,团队创新性地引入JPA中的@Version乐观锁字段作为逻辑时钟,记录用户数据版本。同步服务维护每个用户的当前版本号,只有当接收到版本号更大于已有版本的更新时才执行同步。这样,任何同步回环产生的重复或过旧版本都会被智能忽略,实现了精准的循环检测与拦截。 此方案避免了物理时间戳的依赖,排除了时钟漂移带来的误差,从根本上保障了双向更新的正确性和系统稳定。经过广泛测试,算法符合实际业务需求,保证仅允许密码重置和封禁类操作从旧系统同步,避免了复杂字段的不一致风险。
构建具备分布式数据库特性的数据同步系统 该迁移系统不单是数据拷贝桥梁,更因其设计展现出高可用、故障自恢复、异步一致性等分布式数据库关键特征。用户活跃时流量走新系统,旧系统则作为备份存在;用户不活跃或者发生变更时,旧系统可充当“主库”,在后台将变更同步至新系统,实现故障切换保障业务连续性。 在CAP理论中,系统选择了AP(可用性和分区容忍性)策略,容忍系统在短时间内的弱一致,实现最终一致性,充分符合线上高并发、高可用系统的需要。通过持续监控Kafka主题滞后及故障预警,团队实时掌控同步健康状况,保障迁移平稳完成。 迁移的成功经验与未来展望 KA的用户迁移实践扭转了传统“停机换代”的固有思维,成功实现在业务不中断的情况下完成庞大系统的数据迁移和升级。Debezium与Kafka组合的CDC方案,结合科学的状态机和逻辑时钟机制,为大规模数据同步提供了成熟且易扩展的路径。
经验验证,充分测试环境模拟至关重要,包括数据库集群配置、故障切换流程、流控监测及重试机制。团队协作与跨部门沟通也决定项目能否顺利进行。 随着技术迭代,未来结合GTID支持的MySQL集群和事件驱动架构将进一步简化流程,提升系统稳定性。同时,数据转换能力与异常检测将更加智能化,持续降低人工维护和错误发生。 总结来说,借助Debezium和Kafka,结合合理架构设计、精准的同步算法和周密的运维体系,企业完全有能力安全、高效地完成复杂的用户数据迁移,保障业务平稳过渡,赢得用户信任与市场竞争力。