随着数据量的爆炸性增长,数据库的查询效率成为决定应用性能的核心因素之一。PostgreSQL作为全球最受欢迎的开源关系型数据库,以其灵活性和强大的扩展能力在业界广泛应用。理解其内部查询计划的实现机制,对开发者和数据库管理员来说尤为重要,因为查询计划决定了SQL语句最终的执行路径和效率。所谓查询计划,简单来说,是数据库针对给定SQL语句经过解析、优化后形成的执行策略,它像编译器中的中间表示,既不同于源代码,也非最终的机器码,而是一个结构化且优化过的树形数据结构,指导数据库如何高效地读取数据、执行过滤、连接表以及完成其他复杂操作。深入研究Postgres的查询计划不仅有助于理解数据库的执行逻辑,还能为定制查询调度策略、诊断性能瓶颈和开发执行拦截插件奠定基础。近年来,通过Hook机制,开发者得以拦截Postgres的查询执行过程,获得QueryDesc对象,这一对象完整描述了查询的元数据、计划树以及执行状态,从而实现对查询的重构、分析甚至替换执行逻辑。
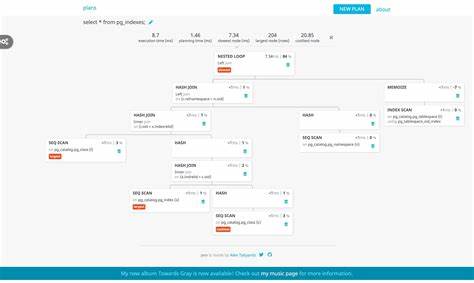
构建这样一套查询计划游走(walking)基础设施,可以将抽象的执行计划转化为可读的SQL字符串,也为后续基于列式数据或面向向量化执行的高级优化提供了入口。安装和开发阶段需要基于Postgres源码环境,开启调试及断言支持,确保能够通过ExecutorRun_hook成功拦截查询执行。通过钩子,可以捕获每条执行语句的计划项,从而分析其具体类型,如SeqScan(顺序扫描),不同Node类型对应不同的执行策略。Postgres内部采用面向对象的设计思潮,所有实体均以Node节点的形式存在。查询计划中的各个节点不仅包含执行指令,还携带关系信息、表达式树、过滤条件等具体内容。由于查询计划类型和内部结构复杂,理解其字段意义及相互关系尤为关键。
例如,QueryDesc结构是执行钩子接收的最顶层查询描述对象,其中的PlannedStmt是经过优化的语句表示,其中planTree字段指向代表执行步骤的Plan节点树。每个Plan节点含有targetlist(查询所需返回的列表达式列表)、qual(过滤条件列表)、与子计划(lefttree、righttree)等,构成完整的查询执行逻辑。区分不同Plan子类类型,如SeqScan表示无索引扫描,而IndexScan可代表基于索引的访问路径,有助于精准定位执行行为。访问查询涉及的表,必须结合rtable(RangeTblEntry列表)获得表的OID,再通过RelationIdGetRelation函数获取实际的关系对象及其元数据信息,从而获取表名、列名等。通过链式访问Var节点,可追溯到具体列,实现表达式和过滤条件的反向解析,将抽象的datums与操作符表示转化为直观的查询字符串。例如,处理OpExpr节点需通过系统缓存查询对应操作符名,结合其操作数构造布尔表达式。
Const节点代表常量值,在解析时依据consttype字段决定如何正确解码Datum数据,如整数型、字符串型等不同处理方法。由于Postgres中任意Node均可能嵌套复合表达式,递归遍历该树即可完整重建SQL语句的各个部分。扩展阅读者还可通过自定义扩展加载机制,结合源码的钩子功能,尝试实现基于自定义执行逻辑的插件。除了输出重构SQL,实现对计划的模拟执行、在存储层或分布式环境中进行优化,均基于对计划树深度理解。Postgres社区鲜有系统性介绍所有钩子接口的文档,结合源码分析与辅助工具,开发者能够自主拓展数据库执行和诊断能力。现代数据库系统对执行计划的开放性为异构计算和智能调度提供了土壤。
借助Open Source优势,能够研究和改写执行路径,是提升数据库性能、兼容多样化硬件的重要手段。未来,构建自动化解析平台,搭配AI技术辅助理解复杂查询逻辑,或将极大降低开发门槛,提升运维和优化效率。为实际业务场景中遇到的性能问题,基于Postgres查询计划层面的分析,不但能快速定位瓶颈,还可推导索引建设、统计信息调整、查询重写等多种调整策略。本文的重要价值就在于指导读者系统性认知Postgres查询计划节点的内部关系,通过具体代码示例,展现如何在查询执行阶段拦截并解析计划,实现在日志中清晰输出并重构SQL。此能力不仅便于教学和调试,也可作为构建数据库中间件、分析代理,甚至实现数据库查询引擎替代方案的坚实技术基础。深入理解Postgres查询计划的结构,联动系统其他模块协同工作,是前沿数据库开发不可或缺的技能。
。