随着人工智能技术的飞速发展,特别是大语言模型(Large Language Models, LLMs)的广泛应用,化学领域正迎来前所未有的挑战与机遇。大语言模型凭借其强大的自然语言处理能力,不仅能够理解和生成复杂的文字内容,还展示出在专业领域提供解决方案的潜力。本文将深入探讨大语言模型在化学知识和推理能力方面的表现,分析其与传统化学专家之间的差异和互补,探讨未来核心发展方向和应用前景。 首先,大语言模型在化学领域的崛起,源自其对海量文本数据的学习能力。通过对数百万篇科学文献、教材、实验报告以及专利等资料的训练,LLMs积累了丰富的化学知识储备。这些模型利用上下文理解,能够回答涉及有机化学、无机化学、物理化学等多个子领域的问题,甚至能辅助设计化学反应路线、预测分子性质。
此外,部分先进系统结合了外部工具,如数据库查询和代码执行,使得推理与知识整合能力大幅增强。 然而,尽管大语言模型在化学问答任务中取得了令人瞩目的成绩,甚至在某些测试中超越了部分人类专家,但其能力依然面临显著局限。模型在处理复杂结构推理、精确计算和科学直觉方面表现不尽如人意。例如,预估核磁共振信号数量、分子对称性分析等任务,对模型来说依然是挑战,这类任务不仅需要知识,更需深入推理和空间想象能力。与之相比,经验丰富的化学家基于多年堆积的实验经验和直觉,能够更准确率地解决此类问题。 此外,模型的知识记忆能力也存在不足。
某些需要专业数据库支持的细节信息,模型无法直接从文本语料中充分掌握。而检索增强生成系统虽能部分弥补这一点,但其效果取决于外部资源的覆盖范围和质量。相比之下,化学专家不仅具备系统化的理论知识,更利用丰富的实验数据和数据库工具完成知识检索,显示出更为灵活和准确的判断力。 另一个关键问题在于模型的置信度估计和输出可信性。研究指出,许多领先大语言模型往往对自己的回答表现出过度自信,这种缺乏自我认知的特质在处理安全性相关化学问题时尤为危险。错误信息不仅误导科研决策,更可能带来安全隐患。
相比人类专家,能够基于经验判断不确定性并谨慎处理模糊信息,当前模型在这方面还有较长的提升空间。 尽管存在这些局限,大语言模型的介入给化学教育和研究模式带来了深远影响。教材上的大量重复性、以记忆为主的知识点,其实已被LLMs高效覆盖,促使教育者重新思考教学重心。未来的化学教育更应该注重培养学生的批判性思维和科学推理能力,因为这些正是现有模型难以复制的。此外,一些基于偏好学习的研究表明,模型在模仿化学家对分子“偏好”的认知尚显不足,这意味着未来借助人机协同进行分子优化和药物筛选仍需大量探索。 从技术角度来看,提升大语言模型在化学领域表现的路径包括扩展训练语料的领域覆盖度,引入结构化的专业数据库,优化模型对分子结构的理解和表达,以及增强生成结果的验证机制。
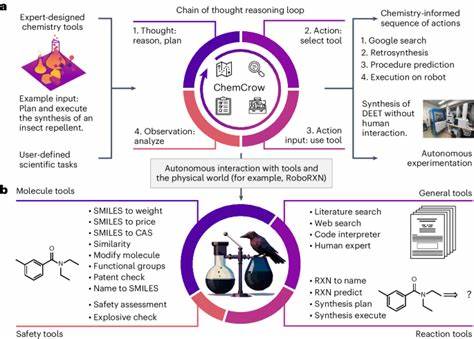
例如,专门对化学符号、SMILES字符串及反应方程进行语义标注、采用多模态集成模型,都是目前研究热点。同时,协同开发开放且标准化的评估平台,对于模型进步和安全性监控至关重要。ChemBench作为一个大型、分门别类细致的化学问答评测框架,为学界和工业界提供了宝贵的评测标准和指标,推动了化学领域中语言模型的规范化发展。 此外,随着人工智能伦理和风险管理意识的增强,化学领域的AI应用还需关注潜在的双重使用风险。设计无毒分子的技术同样可能被滥用于制造有害化学品,公众和初学者对模型输出结果的误解也可能导致安全事故。因此,建立人机交互的安全壁垒和引入必要的人工监督成为使用LLM辅助化学研究的重要保障。
总结来说,大语言模型在化学知识掌握和推理能力上取得了显著突破,一些先进模型已实现超越部分人类专家的表现。然而,其在复杂推理、知识准确性、置信度评估等方面仍有明显不足。未来,要充分发挥其助力化学科研与教学的潜能,需聚焦多模态信息融合、工具增强应用、偏好学习等核心技术发展,同时建立完善的评价和安全监管机制。人类化学家与人工智能的协同合作,被广泛认为是推动学科进步的理想模式。借助成熟的评估平台和持续的技术创新,化学领域有望迎来更加智能、高效的研究新时代。