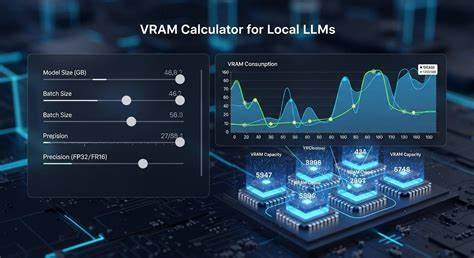
近年来,随着人工智能技术的飞速发展,大型语言模型(Large Language Models,简称LLM)在自然语言处理领域的应用越来越广泛。无论是在自动翻译、文本生成还是代码编写等任务中,LLM都展现出了强大的能力。然而,随着模型参数规模的迅速增长,运行这些模型所需的硬件资源也成为开发者和研究人员关注的焦点。尤其是在本地部署场景下,如何合理计算显存需求,选择合适的模型,成为提升效率和降低成本的关键。为此,本地大型语言模型目录(Local LLMs Directory)应运而生,并配备了显存计算器(VRAM Calculator),帮助使用者根据自身硬件条件进行科学配置。 本地大型语言模型目录汇集了当前市场上表现优异的多个主流LLM,内容涵盖模型提供商、参数规模、上下文容量、模型模态以及发布时间等关键信息。
例如,DeepSeek-R1拥有6710亿参数,支持超过13万的上下文窗口,月度最新版本发布于2024年12月,体现了其先进的技术水平。与之相比,Moonshot AI推出的Kimi K2模型参数规模达到1万亿,展现了未来大模型发展的趋势。此外,阿里巴巴的Qwen系列也持续发力,多个版本覆盖从30亿到4800亿参数,满足不同业务场景的需求。 选择合适的模型不仅要考虑参数大小,还需结合模型上下文窗口大小。上下文容量越大,模型能够处理和记忆的信息越丰富,适合针对长文本理解与生成场景。比如Llama 4 Maverick拥有高达100万的上下文窗口,极大地拓宽了模型应用边界。
另一重要维度是模型的模态支持,即模型能否适应文本、代码等多种数据形式。多模态大模型在提升任务多样性方面发挥着关键作用。 针对本地部署,显存成为制约模型运行的重要瓶颈。基于模型参数数量及量化等级的不同,显存需求变化明显。显存计算器帮助开发者输入自己的硬件配置,精准估算所需显存和模型规格,使得推理、微调以及量化操作更具可控性和经济性。量化技术使得在有限显存条件下依然能够运行大模型,极大扩展了本地使用的可能性。
目前,业内领先的模型包括DeepSeek系列、Kimi K2系列、Qwen系列和GLM系列,涵盖了从几亿到上万亿参数不等的广泛选择。这些模型不仅支持多种推理任务,还能进行细粒度的微调,适合个性化业务需求。另外,开源模型例如GPT-OSS提供了灵活度更高的方案,用户可以基于其基础进行定制开发。 本地化LLM解决方案的兴起反映了对数据隐私和响应速度的不断重视。在不依赖云端环境的情况下,本地部署能够更好地保障关键数据安全,减少网络延迟,提升用户体验。显存计算器的配备显著降低了硬件选型的难度,促进了开发效率的提升。
展望未来,随着硬件性能不断提升和模型架构的优化,预计本地大型语言模型将会拥有更广泛的普及与应用。 同时,社区对于模型性能的评测也趋于标准化。通过统一的评测指标和持续的优化迭代,开发者能够更加科学地选择适合自身需求的模型版本。针对不同的推理、微调及量化场景,目录中提供的相关参数和显存建议成为了不可或缺的参考依据。 总体来看,本地大型语言模型目录和显存计算工具为人工智能开发者提供了极大的便利,从模型选择到硬件匹配,都能精确把控,助力构建高效且经济的AI应用系统。面对日益增长的模型复杂度和算力需求,合理利用这些工具将是实现本地智能服务的关键路径。
持续关注本地LLM生态的动态,掌握最新硬件及软件的发展趋势,将帮助行业从业者抢占技术制高点,推动各类智能应用的创新与落地。 。