在快速发展的人工智能领域,其中一个引人注目的新技术是“检索增强生成”(Retrieval Augmented Generation,简称RAG)。这一概念由研究者Lewis等人在其重要论文《用于知识密集型自然语言处理任务的检索增强生成》中首次提出。RAG技术的兴起,标志着生成式AI的应用进入了一个全新的阶段,它不仅提升了大型语言模型(LLMs)的可靠性和可信度,而且为广大的科学与技术界带来了广泛的应用潜力。 近日,Abhinav Kimothi发布了《检索增强生成的简单指南》(A Simple Guide to Retrieval Augmented Generation)一书,旨在为初学者提供一份易于理解、而又全面的检索增强生成的入门资料。这本书适合数据科学家、数据工程师、机器学习工程师、软件开发者以及对生成AI感兴趣的技术领导者、学生和学者等。通过阅读这本书,读者将能够掌握RAG的基础知识,了解如何构建RAG系统及其实际应用。
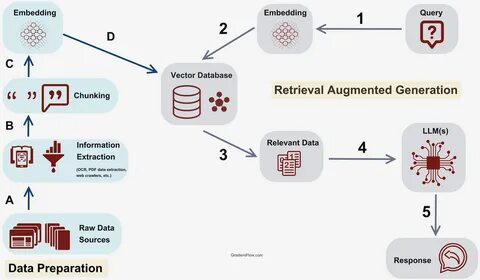
在书中,作者清晰地阐述了什么是“非参数知识库”,并介绍了如何创建这一知识库。通过构建一个RAG系统,读者能深入了解如何设计索引管道以及生成管道,进而实现对上下文的实时交互与响应。这一过程不仅有助于他们掌握技术背后的原理,更能帮助他们在实际的生成AI应用中取得突破性的进展。 书中还深入探讨了RAG系统的评估,强调了准确性、相关性和可信度的重要性。这些评估策略为开发人员提供了一个评估生成AI输出质量的框架,以便于后续不断改进和优化模型。此外,作者还对先进的RAG策略及其不断演进的技术栈进行了分析,帮助读者了解目前RAG领域的发展动态。
由于RAG技术是一个相对较新的领域,因此书中还包括了有关RAG的限制和挑战的讨论。Kimothi着重强调了当前技术所面临的一些问题,并为想要深入研究的读者提供了一些前沿技术的探索方向。这种前瞻性的引导在当前快速发展的AI产业中尤为关键,有助于科研人员在未来的技术更迭中保持敏锐的敏感度。 除了技术知识的传授,书中还包括了多种代码实例,为实际应用提供了切实的支持。例如,在关于索引管道的章节中,书中展示了如何基于维基百科关于2023年世界杯的文章创建知识库。这一过程涉及到的工具和方法如AsyncHtmlLoader、Html2TextTransformer、文本嵌入等,都是前沿的技术,能够帮助开发者轻松应对大数据环境下的信息处理挑战。
在生成管道的章节中,作者依托于前一步骤创建的知识库,通过相似性搜索等功能实现对用户查询的增强,进而生成更为精准和相关的响应。这种实时的交互模式,无疑为用户提供了更为智能的体验,其应用场景不乏在线客服、知识问答、智能助手等。 作为一本仍在不断更新完善中的书籍,《检索增强生成的简单指南》已在Manning早期访问计划(MEAP)中发布了前三个章节。通过参与该计划,读者不仅可以获得当前草稿及未来更新的即时访问权,亦可借此机会提供反馈,从而对最终内容产生影响。同时,参与者还可获得独家折扣和早鸟优惠,充分体现了作者对读者需求的关切。 值得注意的是,为了便于读者进行实际的项目开发,书中也提供了必要的环境设置步骤,包括如何在本地克隆代码库、创建虚拟环境等。
作者明确指出,确保使用Python 3.11.1以上的版本是执行这些代码示例的前提条件,以避免因环境不一致引发的技术问题。 Abhinav Kimothi作为人工智能领域的资深专家,拥有超过15年的数据科学和机器学习的咨询及管理经验。他的专注领域包括应用生成AI,利用上下文智能解决企业需求。他对AI技术不断进步的热情以及探索新兴技术的决心使得这本指南充满了前瞻性和实践性。 总的来看,《检索增强生成的简单指南》不仅是一本面向初学者的入门书籍,更为希望在生成AI领域深耕的专业人士提供了宝贵的知识体系。无论是从RAG的基础概念、系统设计,还是到实际应用案例,书中所涉及的内容都将为读者的学习与开发提供强有力的帮助和启发。
随着AI技术日益融入各行各业,理解并掌握这些前沿的技术趋势显得尤为重要。这本书的发布,标志着检索增强生成作为一种新兴技术,正逐渐成为生成AI的重要支柱。对于未来的AI应用,RAG无疑将为其注入更多的智能和灵活性,为我们带来更加丰富与便捷的数字新时代。