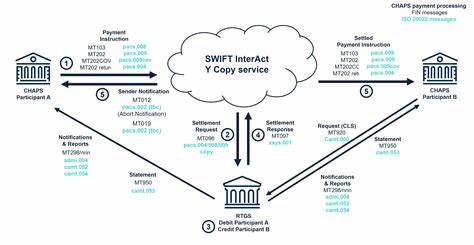
Apache Flink作为当今领先的大数据流处理框架,因其强大的可扩展性和灵活的编程模型,受到众多互联网和技术巨头,如阿里巴巴、LinkedIn、Uber和Netflix的广泛采用。然而,随着应用规模的迅猛扩大,尽管Flink在规模上表现卓越,但其计算效率并未同步提升,导致企业面临较高的基础设施成本和资源浪费。Iron Vector的出现,正是为了解决这一瓶颈,通过创新的本地列式向量化执行技术,为Flink工作负载带来了质的飞跃,最高可实现计算成本减半的效果。Iron Vector利用了现代硬件架构中SIMD(单指令多数据)技术和Apache Arrow的列式内存格式,以原生、无缝集成的方式加速Flink SQL和Table API的执行,无需任何代码修改,用户仅需简单配置即可享受性能提升的红利。传统Flink处理数据时采用的是行式存储,这种方式在流处理上下文中虽逻辑清晰,但其数据访问模式未能充分利用CPU缓存和向量指令集的优势。Iron Vector引入了列式数据布局,通过将相关字段按列连续存储,极大地提升了缓存命中率,减少了数据在内存中的冗余访问,从而达到更优的CPU资源利用率。
同时,Flink的多数数据处理依赖于Java环境,其中Java对SIMD支持有限,尤其是在主要的JDK版本中相关功能还处于预览状态,无法发挥现代CPU的全部潜力。Iron Vector应用Rust和DataFusion打造的高性能运行时,突破了Java虚拟机的性能天花板,利用底层语言的高效内存管理和并行能力,优化了执行路径,显著降低了延迟和计算资源消耗。JSON解析作为流处理中的常见性能瓶颈,原生Flink使用Jackson库,虽然成熟但性能较差。Iron Vector革新这一环节,通过引入更高效的解析方式,实现了对JSON数据的快速处理,进一步提升了整体管道的吞吐量和稳定性。Iron Vector的设计理念并非替代Flink框架,而是作为增强工具,紧密集成于Flink的底层任务调度体系,替换部分StreamTask的子拓扑,保持了Flink生态系统的兼容性和成熟度。通过JNI无复制传输Arrow列式数据批次,将Flink物理计划中SQL查询转换为DataFusion支持的执行计划,实现了跨语言、跨平台的高效运算。
Flink原生的RowKind变更语义得以保留,通过在Arrow批次中附加额外列的方式完美支持插入、更新和删除操作,确保了流处理语义的一致性和准确性。Iron Vector目前支持的主要操作包括投影、过滤、表达式计算及常用系统函数,非常适合流式ETL和数据清洗场景。这些场景中,数据通常是无状态操作,Iron Vector能够在不牺牲Flink灵活性的情况下,实现最高近两倍的执行效率。性能测试显示,在典型Kafka的Avro格式数据源经过SQL转换的流式ETL任务中,Iron Vector能带来高达97%的速度提升,极大提升了处理能力和资源利用率,即使在开启对象重用的情况下,速度提升仍达46%。这种效益能够直接转化为运营成本的大幅降低。对于企业而言,每月5000美元的Flink计算支出,通过启用Iron Vector可以每年节省多达3万美元,或者保持现有成本水平,处理容量翻倍。
这种提升不仅提升了企业对数据的响应速度,也使得大规模流处理系统的经营模式更加灵活且经济。Iron Vector通过支持Kafka的Avro原生格式,避免了数据格式在计算前的多次转换,进一步减少了CPU及内存开销。其未来规划还将涵盖JSON和Parquet文件格式等,扩展对更多流行数据格式的原生支持,最大限度地发挥性能优势。Iron Vector的诞生也契合了数据管理系统逐渐向可组合架构转型的趋势,构建在Rust、Arrow及DataFusion技术栈之上,顺应了当前大数据生态中高性能、本地执行的全新潮流。此外,Iron Vector强化了Flink与其他数据系统间的无缝数据共享能力。例如,Arrow成为数据处理的桥梁,使得ClickHouse、DuckDB及Python数据分析库如Pandas、Polars等都能直接访问共享数据而无需重复转换,极大提升了跨平台数据处理的便捷性和效率。
Iron Vector的加入标志着Flink在向现代流处理技术演进过程中的关键一步,弥补了传统框架在效率方面的短板。它不仅提升了数据处理能力,也为企业在控制成本、提升系统可用性和扩展性方面提供了有力支持。随着支持范围的不断扩大,包括未来的状态ful操作、UDF支持及DataStream API的兼容,Iron Vector将持续推动Flink走向更加智能和高效的数据流处理新时代。总结来看,Iron Vector通过列式向量化计算、大幅度优化内存和指令集利用,成为Apache Flink用户降本增效的重要利器。其零侵入式安装与快速性能提升保证了平滑过渡,为企业节省资源和成本的同时,释放了数据计算潜能。面向未来,Iron Vector不仅将继续丰富功能,还将进一步完善对各种数据格式和业务场景的支持,实现流处理效率的全面提升。
对于寻求提升流处理效率、降低运营成本的企业而言,Iron Vector无疑是助力Apache Flink生态持续创新与发展的关键工具。 。