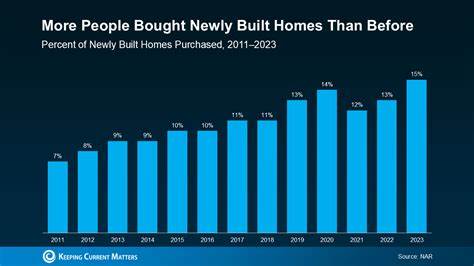
随着生成式人工智能进入更多行业与日常应用,如何在中国境内稳定、合规地访问高性能大模型成为个人开发者、企业和教育机构的共同需求。本文从可用渠道、账号与支付准备、模型能力与场景适配、部署与集成实务、隐私与合规要点、中文提示工程与优化策略等方面,系统呈现无需翻墙即可使用 ChatGPT 中文版(支持 GPT-5、GPT-4o、GPT-o1 与 GPT-o3)的实践路径与注意事项,旨在为不同背景的用户提供可操作的参考与决策依据。 理解可行的访问渠道是首要步骤。国内用户要优先选择官方授权的服务与本地化合作伙伴,这包括在中国境内有正式业务合作的云服务商与软件平台、经授权的移动应用与企业级解决方案提供商、以及经许可部署的行业垂直平台。国内云服务商可能通过合作或授权的方式在本地部署模型推理能力,提供 API、SDK 与控制台管理界面,支持支付宝、微信、银联等本地支付方式与企业级合同结算。个人用户可以通过获得授权的应用商店下载官方或经授权的客户端,或通过合作伙伴提供的网站直接注册并登录使用。
在准备账号与支付信息时,建议提前完成必要的实名认证与企业资质审查。许多本地化平台为防止滥用与确保合规,会要求用户提交手机号码绑定、身份证或营业执照等证明材料,并承担相应的审查流程。对于企业客户,签署合规合同、明确数据使用与保密条款、约定 SLA(服务等级协议)与响应机制是常见流程。支付方面,优先选择支持本地支付手段的平台,避免使用不被支持的海外卡或跨境支付方式,从而保证账单透明与后续对接顺畅。 模型选择与能力评估是核心决策之一。不同型号的 GPT 系列在推理速度、上下文长度、生成质量、对话连贯性与成本上可能存在差异。
对于需要高质量创作、复杂逻辑推理与多轮长对话的任务,通常选择能力更强的模型版本;对于实时性要求高、成本敏感或仅需简单文本处理的场景,可以优先选用轻量级或优化的变体。企业在评估时应关注模型的多语言支持(尤其是中文语义理解与生成)、上下文窗口大小(影响长文档或多轮会话的表现)、自定义能力(如微调或自定义指令)、以及可用的安全过滤机制。建议在实际业务中通过小规模试运行来验证模型在真实数据上的表现与成本效益。 部署与集成方面提供灵活的选择。对于注重敏捷开发与快速迭代的团队,使用云端 API 是最快的上手路径,支持常见的 REST 接口、WebSocket 实时流式返回,以及多种语言的 SDK。API 集成对于内部工具、客户服务机器人、内容生成系统与数据分析管道都非常方便。
对于对数据安全和延迟有更高要求的企业,某些本地化解决方案提供私有化部署或边缘推理选项,可以在企业自有网络或专用云环境中运行模型推理,减少敏感数据外传风险并降低网络延时。无论是哪种部署方式,都应在设计中明确身份认证、限流策略、错误重试与日志审计机制,以确保系统稳定性与可追溯性。 数据隐私与合规是不可忽视的重点。选择服务提供商时务必审核其数据处理政策、是否提供数据不落地或加密传输选项、以及是否支持模型训练数据的排除或删除请求。企业在接入前需要和服务方达成书面协议,明确数据使用范围、保存期限、第三方访问控制与应急响应流程。对处理个人数据或敏感信息的业务,应结合本地法律法规与行业规范落实最小化数据收集、匿名化处理与访问权限分离等技术与管理手段。
在移动端与桌面端使用体验上,国内授权客户端通常提供优化的中文界面、本地支付与消息推送功能,并针对网络条件与终端性能做了加速与降采样策略。使用时可关注客户端是否提供会话管理、导入导出历史记录、多格式输出(如文档、Markdown、代码片段)以及与第三方办公软件的联动插件。对于开发者,关注是否有开放的 webhook、插件框架与生态市场,便于将模型能力嵌入现有工作流与业务系统。 提示工程与中文优化是提升产出质量的关键。撰写中文提示时建议明确角色设定、期望输出格式与上下文约束,必要时使用实例化示例向模型示范期望的表达风格与结构。对于长文本生成或需要引用外部事实的任务,可将关键信息作为系统或上下文提示输入,或分段管理上下文以避免超出模型的上下文窗口。
对话场景应合理设置温度与采样参数以平衡创造性与稳定性,必要时使用后处理规则匹配与校验来过滤不合规或不准确的信息。 成本控制与性能监测需要在实际使用中持续优化。建议在初期通过流量预测与分级策略确定不同任务使用的模型层级,将高成本模型用于高价值输出,将轻量模型用于常规自动化任务。使用 API 时要监控请求频率、响应延时、每次会话的 token 使用量与错误率,基于监控数据调整缓存、批处理和并发限流策略以降低总费用。企业还应关注模型更新策略与兼容性变化,定期评估新版模型的性能改进并在测试环境中验证后再全量推广。 安全防护与滥用防范需要在技术与管理两个维度同时推进。
技术上可以采用输入检测、输出过滤、行为阈值与速率限制来降低模型被利用的风险;管理上应完善账号权限分配、审计日志与应急响应流程。对于面向公众的服务,建议对高风险输入启用更严格的审查,并在用户协议中明确禁止违规用途与责任承担条款。教育与培训方面,应对内部使用者普及模型能力与局限性,提升对生成内容真实性与合规风险的识别能力。 行业应用示例有助于理解落地价值。在客服与智能助理领域,ChatGPT 中文版可以承接常见问答、工单归类、知识库检索与流程引导,提高效率并降低人工成本。在内容创作与市场营销中,模型能辅助撰写文案、生成创意脚本、改写与本地化文本,缩短产出周期。
在软件开发与代码辅助方面,模型可帮助生成示例代码、解释调试思路、编写单元测试与代码注释。在教育与培训场景,模型能提供个性化辅导、题目解析与学习计划建议,但应结合教师监督与作业检查避免替代性风险。在数据分析与决策支持上,结合结构化数据与业务规则,模型可辅助编写报表解读与数据洞见,但关键决策仍需人类复核。 面对误差与偏见问题,需要主动治理。生成模型并非事实数据库,可能出现错误信息或措辞偏差。为降低影响,可构建事实校验层,将模型生成内容与可信数据源比对;对涉敏话题设置更严格的审查与人工复核;针对行业用例建立定制化的领域知识库与规则集以约束输出。
长期来看,定期对模型输出进行抽样审查、收集用户反馈并将反馈用于改进,是提升系统可靠性的有效路径。 升级与迁移策略值得提前规划。随着模型版本迭代,企业应建立灰度发布与回滚机制,评估新版在语义理解、上下文一致性与成本上的变化。对于有微调或链路定制的项目,要关注模型接口与参数的兼容性,确保迁移过程中业务中断最小化。备份会话数据与配置,维持可追溯的变更记录,是降低迁移风险的基础操作。 对于个人用户,选择合适的使用方式可以兼顾体验与成本。
首次使用者可以选择带免费体验额度的平台进行功能试探,熟悉中文提示技巧与平台差异后再考虑付费订阅或按量计费。关注是否提供导出会话、隐私设定与本地备份功能,避免重要对话丢失。对于创作者与专业人士,利用 API 与插件将模型能力集成到写作工具、笔记软件与协作平台中,可以显著提高工作效率。 总结来看,国内稳定访问 ChatGPT 中文版并高效利用 GPT-5、GPT-4o、GPT-o1 与 GPT-o3 等先进模型,核心在于选择合规的服务渠道、做好账号与数据合规准备、根据场景选择合适模型并优化提示工程、构建安全与监控机制以保障稳定性与合规性。无论是个人开发者、创意从业者还是企业用户,理解模型能力边界并结合业务需求进行技术与管理设计,才是把生成式 AI 转换为长期价值的可持续路径。对于正在尝试接入的团队,建议从小规模试点开始,逐步扩展并建立由数据、合规、和运维共同支持的治理体系,确保在合法与安全的前提下最大化模型带来的生产力提升。
。