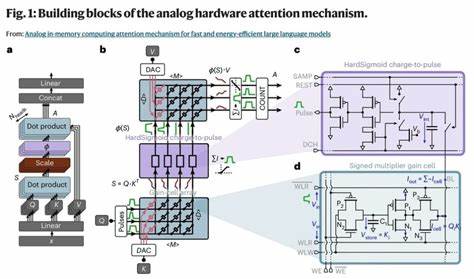
近年来,随着大型语言模型(Large Language Models, LLMs)在自然语言处理领域的卓越表现,人工智能应用迎来了爆发式增长。然而,传统基于GPU的计算平台在处理诸如Transformer模型的注意力机制时面临着严重的延迟和能耗瓶颈。注意力机制作为Transformer网络的核心负责捕捉序列间的依赖关系,其计算复杂度和数据访问需求极高,尤其是在生成式任务中,频繁地更新和存取键值缓存(KV cache)极大地增加了能耗并拖慢响应速度。为了突破传统数字计算的瓶颈,模拟存内计算(Analog In-Memory Computing, AIMC)技术应运而生,成为提升LLMs推理效率的关键方案。模拟存内计算旨在将存储与计算紧密结合,通过硬件电路直接在存储单元中完成矩阵乘法等核心运算,显著减少数据在存储与处理器之间的传输,提高并行度,实现更低的功耗和更快的响应。在最新研究中,基于电荷存储的增益单元(gain cells)被提出用于实现IDM专门设计的注意力机制硬件架构。
增益单元利用存储电容中的电压作为权重存储,通过读出晶体管输出相应的电流,实现模拟形式的点乘累加运算。此类型存储具有快速写入、低能耗和高耐久性等优点,并能实现非破坏性读取,从而支持高度并行的模内计算过程。针对规模较大的LLMs,注意力机制中的键值缓存不断更新,要求内存具备高速写入能力,传统DRAM和SRAM在能耗、密度及写入速度间存在权衡。增益单元介于二者之间,能够提供足够的存储密度并支持动态快速更新,保障KV缓存的持续高效运作。模拟计算过程中对数据数字化转换依赖严重,传统的模数转换器(ADC)功耗和面积较大,削弱了模拟计算的优势。为此,增益单元架构中创新地采用了基于电荷转换脉冲的电路设计,直接将模拟量转换成脉冲宽度调制信号,结合数字脉冲计数器完成数字读出,这种混合模拟-数字方式有效避开高功耗ADC瓶颈,实现了高效的数据处理和转换。
硬件架构采用滑动窗口注意力机制限制注意力范围,降低KV缓存规模,缓解了存储负载,并通过管线化设计使读写操作并行执行,进一步压缩延迟并提升吞吐。每个注意力头内部细分为多个子阵列以分担存储和计算任务,应对大尺寸窗口和嵌入维度的需求,同时保持较低的电阻损耗提升信号完整性。硬件对预训练模型的适配面临诸多挑战,硬件本身的非理想乘法非线性、脉冲编码、激活函数替换(HardSigmoid代替Softmax)、量化层次等限制都使得直接映射预训练权重不可行。为解决此问题,研究团队提出了一套逐层缩放和适配算法,使预训练语言模型在模拟硬件环境中调整其权重分布,最大限度保留性能,且无需从零训练。通过这种硬件感知的微调方法,在保证硬件兼容性的同时,实现了与标准GPT-2框架相当的性能。技术验证方面,基于TSMC 28纳米工艺节点的电路模拟展示了64×64阵列规模的增益单元和脉冲电路,功耗显著下降,单个注意力头的每令牌能耗低至纳焦耳量级,推理延迟缩短至几十纳秒。
与市面主流GPU设备(如Nvidia RTX 4090、H100和Jetson Nano)相比,模拟存内计算架构在能耗和推理速度上分别实现了上万倍与数百倍的优势。面积方面,采用先进的氧化物半导体场效应晶体管(OSFET)工艺,结合三维集成技术,进一步压缩芯片尺寸,使得硬件集成更具实用性与可扩展性。对自然语言理解和生成任务的下游评测证明,硬件模型在ARC、WinoGrande、LAMBADA等语义理解任务中取得与软件实现相似的准确度,展现出良好的泛化与实用潜力。尽管如此,硬件非理想效应仍对模型训练和推理带来一定挑战,研究继续探索更优训练策略和硬件电路优化,以促进性能提升。值得关注的是,模拟存内计算的成功不仅推动了大规模语言模型的硬件加速,也为整体AI算力架构设计提供了新思路。在未来,结合存内计算的其他神经网络组件,如线性层、前馈网络进一步协同优化,将开启更具节能和高速能力的自适应智能系统。
此外,模拟存内计算的应用超越语言模型,有望加速机器视觉、语音识别及多模态融合等领域深度学习的硬件部署。随着器件制造工艺的进步与电路设计的创新,模拟存内计算有望成为下一代人工智能芯片的核心技术基石,助力实现低功耗、高效率和实时响应的智能服务。总结而言,模拟存内计算注意力机制通过紧密结合存储与计算,利用增益单元和混合模拟数字电路,使大规模语言模型在推理时获得前所未有的速度与能效优势。其完整的硬件-算法协同优化策略不仅保证了模型的准确性,也极大缩减了能源消耗和运算延迟,标志着人工智能硬件迈向更绿色、快速的新时代。这一创新技术为构建未来大规模生成式AI系统奠定坚实基础,推动智能计算进入更高效、智能的轨道。 。